Table of Contents
Note
This is a work in progress.
The Greek New Testament was copied by hand for almost fifteen centuries until the advent of mechanized printing provided an alternative means of propagation. Translations into other languages were produced as well. Some of these — such as the Latin, Coptic, and Syriac versions — appeared early and thus preserve ancient states of the text. Patristic citations form another class of evidence that allows varieties of the text to be associated with particular localities and epochs. Analysis of textual variation allows relationships between these three classes of witnesses — manuscripts, versions, and patristic citations — to be explored. This article applies various kinds of analysis to textual variation data collected from a variety of sources. The analysis results offer complementary views of the textual space occupied by these venerable witnesses to the New Testament text.
As with every widely read work from antiquity, the New Testament exhibits textual variation introduced by scribes and correctors. Sites where textual variation occurs are identified by comparing extant witnesses of the text.[1] Differences may be classified as orthographic or substantive. Orthographic variations are often ignored as they only affect the surface form of a text and not its meaning. Substantive variations do affect meaning: they are often called readings or variants The list of witnesses that support a particular reading of a particular variation site is known as the reading's attestation. A list of all readings at a variation site along with the attestation of each reading is called a variation unit. Critical editions often present variation units in an apparatus. The present study is based on analysis of data sets extracted from critical editions, monographs, journal articles, dissertations, or online databases.
There is an ongoing effort to establish the initial text which stands behind the range of texts found among surviving witnesses of the New Testament.[2] The most important witnesses for establishing the initial text fall into these categories:
Greek manuscripts
ancient versions
patristic citations.
Greek manuscripts are the primary witnesses to the text of the New Testament. Ancient versions are early translations of the Greek text into languages such as Latin, Coptic, Syriac, and Armenian. It is often possible to establish which Greek reading a version supports by translating its text at a variation site back into Greek. Patristic citations are quotations of the scripture by Church Fathers. Which reading was in a Church Father's copy of the text at a particular variation site can often be discerned if that part of the text is covered by one of his quotations.
A large proportion of the textual evidence disappeared long ago. Even a comprehensive data set that includes all readings of all extant witnesses is still a mere sample of what once existed. In general, the older the copy, the more likely it is to have been lost. This loss of data presents a fundamental problem: if extant texts do not represent the oldest copies then the survivors will give a skewed impression of the initial text. Happily, there is a way forward: if like texts are grouped and more or less accurate representations of the archetypal texts that gave rise to the groups can be reconstructed then these archetypes have a claim to being more representative of the ancient text. In addition, the extant copies provide data for estimating how accurately the copyists practiced their art. Armed with a knowledge of the number of generations of copies and typical rates of substituting one reading for another per generation, it is possible to say how much the original text is likely to differ from the initial text recoverable from extant copies. While raw data that could be used for the purpose is presented below, I do not propose to reconstruct hypothetical archetypes or estimate rates of change here. Instead, this article will focus on presentation and analysis of available data to explore grouping among the extant texts.[3]
Even though much is lost, a stupendous amount of evidence remains. There are many thousands of manuscripts in Greek, Latin, Syriac, Armenian, and other languages. Patristic citations are also very numerous. Given such a great cloud of witnesses, it can be difficult to see where each one stands in relation to the others. Fortunately, various methods of statistical analysis can be applied to data sets which relate to textual variation in order to explore relationships among the witnesses.
Analysis might begin from a number of starting points. One suitable place to begin is a data set derived from a critical apparatus which gives attestations (i.e. lists of witnesses) in support of readings found at variation sites. In nearly all cases, practical considerations restrict an apparatus to presenting a sample of extant texts. Results obtained by analysis of these data sets are therefore provisional because it is always possible that including further data would produce different results. However, it is reasonable to expect that analysis results will approximate those that would be obtained if a more comprehensive data set were analysed provided that the sample is sufficiently large and has been selected without systematic bias.
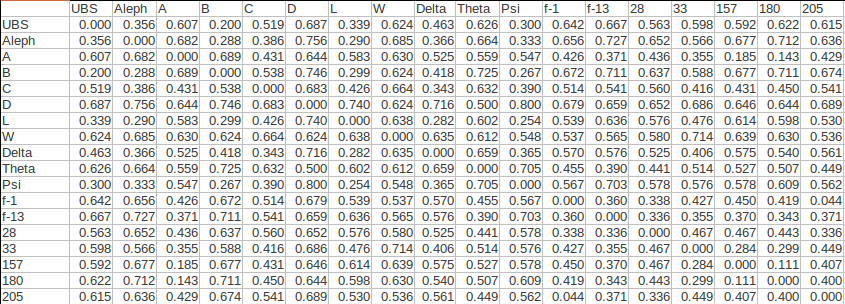
The information contained in an apparatus must first be encoded as illustrated by reference to this entry from the fourth edition of the United Bible Societies' Greek New Testament (UBS4):

The data sets presented in this article use a number of encoding conventions. Exotic characters and superscripts can cause problems when plotting analysis results so witness identifiers (i.e. sigla) are Romanized and superscripts are replaced by hyphenated sequences of characters. Apart from these changes, the method of identifying witnesses used by the source of a data set is usually retained. Be warned, dear reader: this approach is liable to cause confusion when two sources use different identifiers for the same witness. For example, Codex Sinaiticus may be identified as Aleph or 01. Also, the critically established text used in the INTF's Editio Critica Maior may be referred to as A (for Ausgangstext), making it easy to confuse with the A often used to represent Codex Alexandrinus.
When it comes to encoding apparatus entries, the textual states found among the witnesses
can be represented by numerals, letters, or other symbols. In the present example, the first
reading is encoded as 1, the second as 2, and so on. The state of a
witness is classified as undefined and encoded as NA (for not
available) when it is not clear which reading the witness supports. For
manuscripts this may be due to physical damage or because the manuscript does not include the
section of text being examined; for versions, it may not be clear which state of the Greek
text is supported by a back-translation of the version; for patristic citations, the reading
of a Church Father's text may be unclear if the quotations are not exact (e.g. adaptations,
allusions, or quotations from memory) or if different witnesses of the Church Father's text
have different readings. In the present example, a number of versions (Latin, Syriac, Coptic)
and patristic citations (e.g. those of Irenaeus, Ambrose, Chromatius, Jerome, and Augustine)
are treated as undefined because it is not clear which readings they support at this variation site.[4]
Table 1. Codes for readings (Mark 1.1, UBS4)
| Code | Variant | Attestation |
|---|---|---|
| 1 | Χριστου υιου θεου | UBS Aleph-1 B D L W 2427 |
| 2 | Χριστου υιου του θεου | A Delta f-1 f-13 33 180 205 565 579 597 700 892 1006 1010 1071 1243 1292 1342 1424 1505 Byz E F G-supp H Sigma Lect eth geo-2 slav |
| 3 | Χριστου υιου του κυριου | 1241 |
| 4 | Χριστου | Aleph Theta 28-c syr-pal arm geo-1 Origen Asterius Serapion Cyril-Jerusalem Severian Hesychius Victorinus-Pettau |
| 5 | omit | 28 Epiphanius |
| NA | undefined | it-a it-aur it-b it-c it-d it-f it-ff-2 it-l it-q it-r-1 vg syr-p syr-h cop-sa cop-bo Irenaeus Ambrose Chromatius Jerome Augustine Faustus-Milevis |
Encoded readings are entered into a data matrix which has a row for every witness and a column for every variation site. The appropriate code is entered at the cell corresponding to a particular witness and variation site, namely that cell located at the intersection of the witness row and variation site column. Manuscript correctors are treated as separate witnesses, as are supplements.

The next step is to construct a distance matrix which tabulates the simple matching distance between each pair of witnesses sufficiently represented in the data set. The simple matching distance between two witnesses is the proportion of disagreements between them at those variation sites where the textual states of both are defined. Being a ratio of two pure numbers, this quantity is dimensionless (i.e. has no unit). It varies from a value of zero for complete agreement to a value of one for no agreement.[5] A witness only qualifies for inclusion in a distance matrix if all distances for that witness are calculated from at least a minimum number of variation sites. This constraint is intended to reduce sampling error to a tolerable level. It is enforced by a vetting algorithm that progressively drops witnesses with the least numbers of defined variation sites until all distances in the distance matrix are guaranteed to have been calculated from a minimum acceptable number of sites. The minimum acceptable number for the distance matrices of this study is nearly always set at fifteen.[6]
Various analytical methods can applied to a data set derived from a critical apparatus to
explore relationships between witnesses. All of the results presented in this article are
obtained using a statistical computing language called R. The analysis
is performed by means of R scripts written by the author which are
available here. The R program and
additional packages (e.g. cluster, rgl, ape) required
to run the scripts can be installed using instructions provided at the R web site.
Readers are encouraged to use the scripts. There are various ways to run a script once the
R environment is installed. For users who prefer a command line
interface, typing R into a terminal window provides an R
prompt. (It helps to change to the directory which holds the scripts before launching
R.) A command can then be entered in order to run a script. As an
example, the command source("dist.r") typed at the R
prompt causes the dist.r script to
construct a distance matrix from the specified data matrix. Parameters such as paths to input
and output files are specified in the scripts, which users are free to edit.
The data sets analysed in this article derive from various sources. Each source is assigned an identifier based on the author or party who produced it. A source is often used to produce data sets for a number of New Testament sections such as individual gospels and letters. Each analysis result is keyed to the relevant section and source identifier so that its underlying data set can be identified.
The data sets generally retain the symbols used by their associated sources to represent New Testament witnesses. Some represent manuscripts by Gregory-Aland numbers (e.g. 01, 02, 03, 044) while others use letters or latinized forms (e.g. Aleph, A, B, Psi). These symbols carry through to the analysis results. In INTF data, ECM or A (for Ausgangstext or initial text) represents the text of the Editio Critica Maior. The A for Ausgangstext in INTF data sets should not be confused with the A for Codex Alexandrinus in other data sets. Also beware of confusing texts when the same letter (e.g. D, E, F, G, H, K, L, P) refers to different manuscripts in different parts of the New Testament. Abbreviations UBS, WH, and TR stand for the texts of the United Bible Societies' Greek New Testament, Westcott and Hort's New Testament in the Original Greek, and the Textus Receptus, respectively. Maj, Byz, and Lect stand for majority, Byzantine, and lectionary texts, respectively. The relevant printed editions should be consulted for explanations of what these group symbols represent.
A source may be in the form of apparatus entries, tables of percentage agreement, or lists of pairwise proportional agreement. If the source is an apparatus then it is used to construct one data matrix per desired section. Each data matrix includes those witnesses and variation sites covered by the apparatus, using symbols such as numerals or letters to encode reported textual states (i.e. readings). A distance matrix is then constructed from the data matrix. If the source only reports percentage or proportional agreement between witnesses then a distance matrix is constructed directly from the agreement data and no data matrix is produced. Distances are usually specified to three decimal places regardless of whether this level of precision is warranted.
Analysis cannot proceed if a distance matrix has missing entries. This problem can be avoided by manually producing multiple distance matrices from the same source data, each omitting a particular witness whose inclusion would create an empty cell. This is done for a number of the distance matrices presented below, including Brooks' table for John (where there is a missing cell for C and Old Latin j) and Fee's table for John 1-8 (which lacks cells where the first hand and corrector intersect for P66 and Aleph).
Distance matrices are normally obtained by applying the default vetting algorithm, which drops the least defined witness of each pair used to calculate a distance until all distances are calculated from the minimum acceptable number of variation sites where both are defined, which is normally fifteen. In some cases, an alternative approach is used which forces a particular witness to be retained provided it has enough defined variation sites at the outset. Examples include UBS2 distance matrices for Matthew, Mark, John, and Acts where Alexandrinus (A), Ephraemi Rescriptus (C), Sinaiticus (Aleph), and P45 have been retained due to their importance.
It is helpful to know what analysis results look like when there is no clustering among the objects being analysed. (Generic terms such as object, observation, case, or item may be used for the things being compared when they are not necessarily New Testament witnesses.) We have a natural facility for recognising group structure but are also prone to mistake a purely random distribution of items for a cluster. One way to avoid this kind of error is to be familiar with analysis results produced from a data set that has no group structure. With this purpose in mind, a control data set may be generated which is analogous to its model data set in various respects (e.g. number of objects, number of variables, mean distance between objects) but has no actual clustering among its objects.
A control data set is generated by performing c trials to randomly select one
of two possible states (1 and 2) then repeating this r
times to produce a data matrix with r rows of objects and c columns
of variables. The generator aims to produce objects which have a mean distance of
d between them. Values for r, c, and d
are derived from the model: r is the number of objects in the model distance
matrix; c is the rounded mean number of variables in the objects from which the
model distance matrix was calculated; and d is the mean of distances in the model
distance matrix. The control data matrix is then used to calculate a control distance matrix
which has the same number of objects as the model and approximately the same mean distance
between objects.[7]
The binomial distribution predicts the range of distances expected to occur between pairs of objects generated in this way. A 95% confidence interval is the range of distances expected to occur for 95% of randomly generated cases. Only 5% of distances between two randomly generated objects fall outside the upper and lower limits defined by this interval. A distance outside this range, either less or more, is statistically significant in the sense that it is unlikely to happen by chance (though there is a 5% chance it will). A distance outside the normal range defined by the 95% confidence interval indicates an adjacent or opposite relationship between two objects: adjacent if the distance is less than normal and opposite if greater.[8]
While distances outside the normal range are unlikely to occur by chance, a distance inside that range does not necessarily imply lack of relationship between two objects: a relationship between the two may exist but it is not possible to say so with confidence. The relative size of the normal range contracts as the number of places compared increases so a distance which is not statistically significant in one data set may be statistically significant in another which includes more variation sites.
The following table presents the data sets and their sources. Links in the table provide
access to data and distance matrices which are formatted as comma-separated
vector (CSV) files so that they can be downloaded and imported into a spreadsheet
program. A distance matrix is always provided but a data matrix is only included if one has
been constructed. If there is no data matrix then NA for not
available is entered in the relevant column.
Table 2. Data sets and their sources
| Source | Description | Section | Data matrix | Distance matrix |
|---|---|---|---|---|
| Brooks | Tables of percentage agreement from James Brooks' New Testament Text of Gregory of Nyssa covering: Matthew (table 1, 58-9); Luke (table 7, 90-1); John (table 13, 138-9); and Paul's Letters (table 18, 254-5). These were transcribed by Richard Mallett. | Matthew | NA | → |
| Luke | NA | → | ||
| John (C) | NA | → | ||
| John (it-j) | NA | → | ||
| Paul's Letters | NA | → | ||
| CB | Data matrices for each Gospel compiled by Richard Mallett using Comfort's New Testament Text and Translation Commentary and Comfort and Barrett's Text of the Earliest New Testament Greek Manuscripts. | Matthew | → | → |
| Mark | → | → | ||
| Luke | → | → | ||
| John | → | → | ||
| Cosaert | Data matrices for each Gospel compiled from apparatus entries in Carl P. Cosaert's Text of the Gospels in Clement of Alexandria. | Matthew | → | → |
| Mark | → | → | ||
| Luke | → | → | ||
| John | → | → | ||
| Cunningham | Tables of percentage agreement for the Gospel of John and Paul's Letters from Arthur Cunningham's “New Testament Text of St. Cyril of Alexandria,” 421-2 and 753. Associated tables of counts are on pages 423-4 and 754. | John | NA | → |
| Paul's Letters | NA | → | ||
| Donker | Data matrices for Acts, the General Letters, and Paul's Letters from Gerald Donker's Text of the Apostolos in Athanasius of Alexandria. Gerald Donker and the SBL have made this data available through an archive located at sbl-site.org/assets/pdfs/pubs/Donker/Athanasius.zip. May their respective tribes increase! | Acts (all) | → | → |
| Acts 1-12 | → | → | ||
| Acts 13-28 | → | → | ||
| General Letters | → | → | ||
| Paul's Letters | → | → | ||
| Romans | → | → | ||
| 1 Corinthians | → | → | ||
| 2 Cor. - Titus | → | → | ||
| Hebrews | → | → | ||
| EFH | Data used by Jared Anderson for his ThM thesis, “Analysis of the Fourth Gospel in the Writings of Origen.” The data was originally collected by Bart D. Ehrman, Gordon D. Fee, and Michael W. Holmes for their Text of the Fourth Gospel in the Writings of Origen. (Bruce Morrill did the statistical analysis presented in that volume.) A revised version of Anderson's thesis will be published in SBL's New Testament in the Greek Fathers series. | John | → | → |
| Ehrman | Table of percentage agreement for the Gospel of Matthew from Bart Ehrman's Didymus the Blind and the Text of the Gospels. This was transcribed by Richard Mallett. | Matthew | NA | → |
| Fee | Tables of percentage agreement from three articles by Gordon Fee: (1) a table covering Luke 10 from “The Myth of Early Textual Recension in Alexandria”; (2) tables covering John 1-8, John 4, and John 9 from “Codex Sinaiticus in the Gospel of John”; (3) another table covering John 4 but including patristic data from “The Text of John in Origen and Cyril of Alexandria.” Two distance matrices are produced for each table of percentage agreement with a blank entry for agreement between the first hand and corrector of a manuscript. | Luke 10 | NA | → |
| John 1-8 | NA | → | ||
| John 1-8 (corr.) | NA | → | ||
| John 4 | NA | → | ||
| John 4 (corr.) | NA | → | ||
| John 4 (pat.) | NA | → | ||
| John 4 (pat., corr.) | NA | → | ||
| John 9 | NA | → | ||
| John 9 (corr.) | NA | → | ||
| Hurtado | Tables of percentage agreement from Larry Hurtado's Text-Critical Methodology and the Pre-Caesarean Text. There is one table for each of the first fourteen chapters of the Gospel of Mark, one for Mark 15.1-16.8, and another for places where P45 is legible. Data from an augmented version of Hurtado's P45 table is presented below in the Mullen source entry. | Mark 1 | NA | → |
| Mark 2 | NA | → | ||
| Mark 3 | NA | → | ||
| Mark 4 | NA | → | ||
| Mark 5 | NA | → | ||
| Mark 6 | NA | → | ||
| Mark 7 | NA | → | ||
| Mark 8 | NA | → | ||
| Mark 9 | NA | → | ||
| Mark 10 | NA | → | ||
| Mark 11 | NA | → | ||
| Mark 12 | NA | → | ||
| Mark 13 | NA | → | ||
| Mark 14 | NA | → | ||
| Mark 15.1-16.8 | NA | → | ||
| Mark (P45) | NA | → | ||
| INTF-General | Distance matrices derived from information in a database related to the INTF's Novum Testamentum Graecum: Editio Critica Maior: Catholic Letters volumes. The INTF kindly granted access to this data. | James | NA | → |
| 1 Peter | NA | → | ||
| 2 Peter | NA | → | ||
| 1 John | NA | → | ||
| 2 John | NA | → | ||
| 3 John | NA | → | ||
| Jude | NA | → | ||
| INTF-Parallel | Distance matrices made from tables located at http://intf.uni-muenster.de/PPApparatus/. These present data related to Strutwolf and Wachtel (eds.), Novum Testamentum Graecum: Editio Critica Maior: Parallel Pericopes. The INTF has generously provided open access to this data. | Matthew | → | → |
| Mark | → | → | ||
| Luke | → | → | ||
| John | → | → | ||
| Mullen | Data extracted from Roderic Mullen's The New Testament Text of Cyril of Jerusalem. Two data sets have been prepared for the Gospel of Mark: one is a data matrix based on citations isolated by Mullen (112-7); the other is a distance matrix corresponding to a table of percentage agreement which relates to the parts of Mark's Gospel covered by P45 (41). Mullen based the latter on data compiled by Larry Hurtado then added other texts such as Family 1, 28, 157, and 700 (40, n. 81). | Mark | → | → |
| Mark (P45) | NA | → | ||
| Osburn | Tables of percentage agreement for Acts and Paul's Letters from Carroll Osburn's Text of the Apostolos in Epiphanius of Salamis. Richard Mallett transcribed these tables. | Acts | NA | → |
| Paul's Letters | NA | → | ||
| Racine | Table of percentage agreement for Matthew's Gospel from Jean-François Racine's Text of Matthew in the Writings of Basil of Caesarea. This was transcribed by Richard Mallett. | Matthew | NA | → |
| Richards | Table of percentage agreement from W. L. Richards' Classification of the Greek Manuscripts of the Johannine Epistles (72, 76-84). | 1 John | NA | → |
| UBS2 | Tables of percentage agreement compiled from the apparatus of the second edition of the UBS Greek New Testament by Maurice A. Robinson. The tables were originally presented in Robinson's “Determination of Textual Relationships” and “Textual Interrelationships.” They were transcribed by Claire Hilliard and Kay Smith. | Matthew | NA | → |
| Matthew (A) | NA | → | ||
| Mark (C) | NA | → | ||
| Luke | NA | → | ||
| John (Aleph) | NA | → | ||
| Acts (Aleph) | NA | → | ||
| Acts (P45) | NA | → | ||
| UBS4 | Data matrices constructed from the apparatus of the fourth edition of the
UBS Greek New Testament. (The UBS4 apparatus includes minuscule
2427, which is now regarded as a forgery. The data for this manuscript has been retained
for the sake of interest; dropping it would have little effect on analysis results.)
Richard Mallett constructed the matrices for Mark, 2 Corinthians, and Revelation. A
substantial part of the matrix for Matthew was encoded by Mark Spitsbergen. (Only the
first fourteen chapters of Matthew are presently covered.) In some cases, the evidence for
a number of similar witnesses is consolidated to produce a group reading. For example, the
majority reading of vg-cl, vg-st, and vg-ww is counted as the reading of the Vulgate (vg)
in 1 John. Matrices for Mark derived as controls or by excluding readings found in
representatives of five textual groups (B = Vaticanus, Byz = Byzantine, it-ff-2 = Old
Latin ff2, f-1 = Family 1, vg = Jerome's Vulgate) are included
as well. PAM analysis (see below) was used to select the representatives. Variants were
excluded by script mask.R, which for each witness
drops (by substituting NA) those readings that match the representative
text. |
Matthew 1-14 | → | → |
| Mark | → | → | ||
| Mark (control) | → | → | ||
| Mark (it-e) | → | → | ||
| Mark (it-k) | → | → | ||
| Mark (Jerome) | → | → | ||
| Mark (non-B) | → | → | ||
| Mark (non-Byz) | → | → | ||
| Mark (non-f-1) | → | → | ||
| Mark (non-it-ff-2) | → | → | ||
| Mark (non-vg) | → | → | ||
| Mark (Origen) | → | → | ||
| Mark (P45) | → | → | ||
| 1 Peter | → | → | ||
| 1 John | → | → | ||
| 2 Corinthians | → | → | ||
| Hebrews | → | → | ||
| Revelation | → | → | ||
| Wasserman | Tables of proportional agreement from Tommy Wasserman's “Patmos Family of New Testament MSS” covering Matt 19.13-26, Mark 11.15-26, Luke 13.34-14.11, John 6.60-7.1, and the Pericope Adulterae (usually John 7.53-8.11). The underlying collations used a reconstructed text to represent Family Π in Matt 19.13-26 and the Pericope Adulterae, which text is labelled f-Pi in the analysis results. | Matthew 19.13-26 | NA | → |
| Mark 11.15-26 | NA | → | ||
| Luke 13.34-14.11 | NA | → | ||
| John 6.60-7.1 | NA | → | ||
| PA | NA | → |
This study presents results obtained by applying the following analysis methods to the data sets:
ranked distances
classical multidimensional scaling (CMDS)
divisive clustering (DC)
neighbour joining (NJ)
partitioning around medoids (PAM).
These analysis modes will now be introduced by reference to two data sets:
Clusters may be isolated by inspecting a CMDS or NJ plot, cutting a DC dendrogram, or producing a partition using PAM analysis. Similar objects tend to be similar distances from a reference object, near each other in a CMDS plot, in the same branch of DC and NJ plots, and in the same group of a PAM partition. The more eccentric an object when compared to others in the data set, the more isolated it will appear in analysis results. If an object is mixed, being comprised of a mixture of states characteristic of differing groups, then a CMDS result will locate it between the relevant groups, proportionally closer to those whose characteristics it most often contains. In DC, NJ, and PAM analysis, a slight change in the distance matrix can cause a mixed object to leap from one branch, cluster, or group to another.
The respective analysis results are often but not always consistent. If all of the analysis results point to the same conclusion with respect to implied clustering then that can be taken as a firm result; if they differ then each result needs to be handled with due caution. The distance matrix remains the final arbiter when the affiliation of an object is not clearly indicated by concurrence of analysis results. When the classification of an object is uncertain, further information may produce a more definite result. However, if an object has a mixed nature then it may remain difficult to classify as anything but a mixture. A mixed object will tend to be isolated unless other objects happen to have similar mixtures of states.
One aim of New Testament textual research is to recover the initial text, namely the common ancestor of extant New Testament texts. Some aspects of the results produced by the analysis modes used in this study can be interpreted in terms of temporal development. In particular, there may be points of contact between the the family tree of New Testament texts and the tree-like structures produced by divisive clustering and neighbour joining. However, these tree-like analysis results do not provide unequivocal guidance on the location of the initial text. Any node (i.e. junction) or leaf (i.e. terminal) of a DC or NJ tree could be closest to the initial text. If one were to make a string model of such a tree, with knots at every node tying together string segments of the appropriate lengths, the model could be picked up at any node or leaf. The point being held would become a new tree root so there would be as many possible trees as the number of nodes and leaves. The trick is to decide where the root of the tree is located, a topic which will occupy the field of New Testament textual research for some time to come. The Coherence-based Genealogical Method (CBGM) developed by the INTF can be used to investigate whether the witnesses in one branch are closer to the initial text than those in another.[9] Phylogenetic techniques such as described in Spencer, Wachtel and Howe's “Greek Vorlage of the Syra Harclensis” can also be used to investigate the priority of texts. Yet another possibility is to see where texts reconstructed from early patristic citations are located in trees produced by DC and NJ analysis.
Ranking involves selecting a reference object then extracting its row of the distance matrix. Entries in that row are then ordered by increasing distance from the reference. As an example, the following ranks witnesses in the UBS4 data set for the Gospel of Mark by distance from minuscule 205, which is a member of Family 1. The reference witness (i.e. 205) is a distance of zero from itself and would stand at the head of the list if included.[10]
Table 3. Ranked distances from 205 (Mark, UBS4)
| f-1 (0.044); Lect (0.328); 28 (0.336); 1505 (0.367); G (0.370); f-13 (0.371); Byz (0.371); geo (0.372); 1424 (0.377); 1241 (0.379); 1292 (0.381); 597 (0.384); 1243 (0.386*); slav (0.391*); 1006 (0.393*); 1010 (0.394*); 180 (0.400*); E (0.400*); 157 (0.407*); 700 (0.414*); 1071 (0.414*); syr-s (0.417*); H (0.424*); A (0.429*); 565 (0.435*); F (0.435*); it-l (0.439*); vg (0.442*); Sigma (0.444*); syr-p (0.445*); Theta (0.449*); 33 (0.449*); Augustine (0.451*); arm (0.455*); it-q (0.457*); syr-h (0.457*); 1342 (0.460*); 579 (0.464*); syr-pal (0.471*); it-aur (0.478*); N (0.500*); 892 (0.511*); eth (0.512*); it-f (0.514*); L (0.530*); W (0.536*); C (0.541*); it-i (0.557*); Delta (0.561); Psi (0.562*); cop-bo (0.571); cop-sa (0.573); it-ff-2 (0.577); it-c (0.578); it-r-1 (0.589); it-b (0.602); 2427 (0.612); UBS (0.615); it-a (0.626); Aleph (0.636); it-k (0.656); B (0.674); it-d (0.677); D (0.689) |
Statistical analysis shows what range of distances is expected to occur between artificial objects comprised of randomly selected states. Distances in this normal range (i.e. those for 1243, slav, ..., Psi) are marked by asterices to show they are not statistically significant. Some texts (i.e. f-1, Lect, ..., 597) have an adjacent relationship to minuscule 205 while others (i.e. Delta, cop-bo, ..., D) are opposite.
A ranked list of distances from one member of the control data set shows what to expect for unrelated objects. The 95% confidence interval calculated using the binomial distribution with parameters derived from the model data set has lower and upper bounds of 0.374 and 0.553, respectively. (An interval of this kind can be compactly written as [0.374, 0.553].) As can be seen, distances in the control data set tend to fall within these bounds.[11]
Table 4. Ranked distances from R1 (Mark, UBS4, control)
| R5 (0.382*); R11 (0.382*); R17 (0.382*); R20 (0.398*); R15 (0.407*); R22 (0.423*); R42 (0.423*); R46 (0.423*); R64 (0.423*); R8 (0.431*); R25 (0.431*); R38 (0.431*); R39 (0.431*); R45 (0.431*); R2 (0.439*); R27 (0.439*); R57 (0.439*); R4 (0.447*); R10 (0.447*); R31 (0.447*); R32 (0.447*); R53 (0.447*); R34 (0.455*); R54 (0.455*); R58 (0.455*); R14 (0.463*); R21 (0.463*); R28 (0.463*); R44 (0.463*); R47 (0.463*); R51 (0.463*); R55 (0.463*); R56 (0.463*); R59 (0.463*); R3 (0.472*); R12 (0.472*); R35 (0.472*); R36 (0.472*); R9 (0.480*); R13 (0.480*); R50 (0.480*); R61 (0.480*); R23 (0.488*); R29 (0.496*); R41 (0.496*); R49 (0.496*); R24 (0.504*); R30 (0.504*); R63 (0.504*); R7 (0.512*); R16 (0.512*); R18 (0.512*); R19 (0.512*); R40 (0.512*); R43 (0.512*); R6 (0.520*); R33 (0.520*); R37 (0.520*); R48 (0.520*); R62 (0.520*); R65 (0.520*); R52 (0.537*); R60 (0.561); R26 (0.569) |
A list of ranked distances can be produced for every object in a data set. While clustering among members of the data set might be discerned from lists of this kind, the other analysis modes are better suited to discovering inherent group structure.
Classical multidimensional scaling finds the set of object coordinates which best reproduces the actual distances between objects in the distance matrix. A plot of these coordinates shows how the objects are disposed with respect to one another when all distances are considered. This study refers to such a plot as a map and uses the term textual space for the space obtained when the objects are textual witnesses.
Achieving a perfect spatial representation of a distance matrix may require any number of dimensions up to one less than the number of objects. This presents a problem when a large number of objects is being examined because our spatial perception is three-dimensional. Fortunately, three dimensions is often sufficient to achieve a reasonably good approximation to the actual situation. CMDS analysis produces a coefficient called the proportion of variance which indicates how much of the information contained in a distance matrix is explained by the associated map. This coefficient ranges from a value of zero to one, with a value of one indicating that the map is a perfect representation of the entire set of actual distances.
The CMDS map obtained from the UBS4 data set for Mark's Gospel shows that the textual space formed by New Testament witnesses has structure. The associated proportion of variance figure is 0.51, meaning that about half of the entire distance information is captured in the plot.[12]
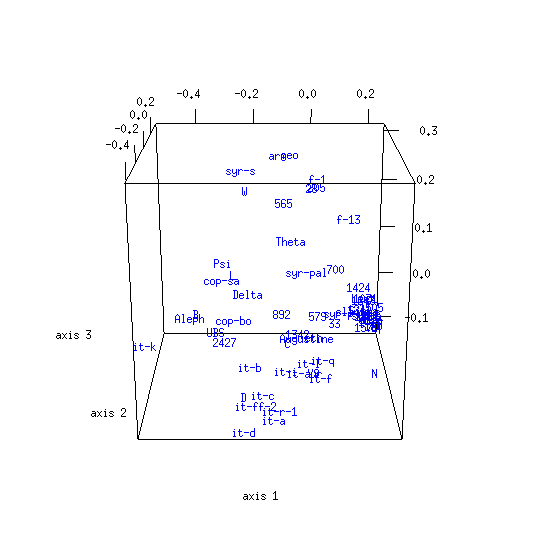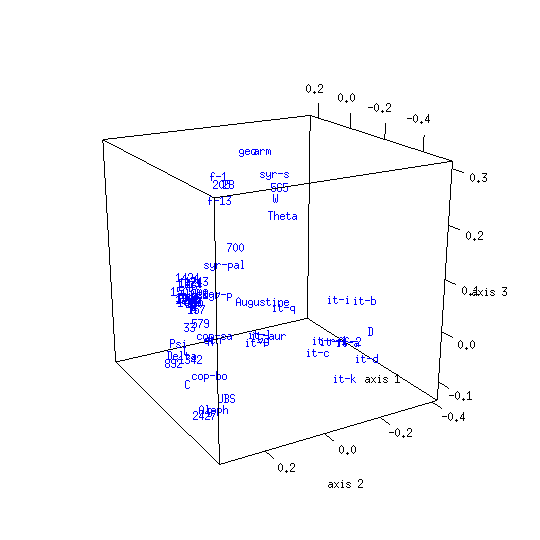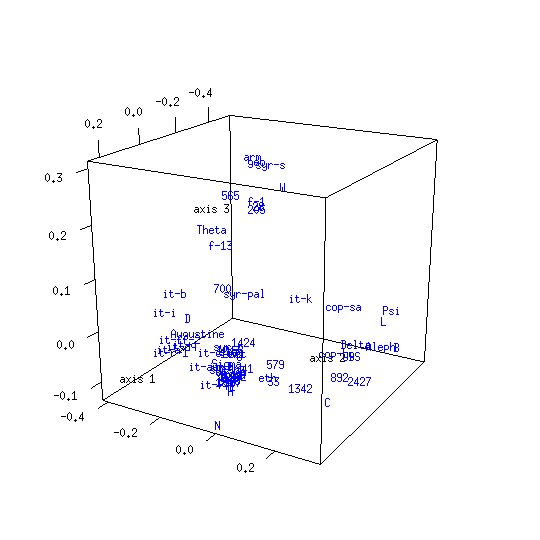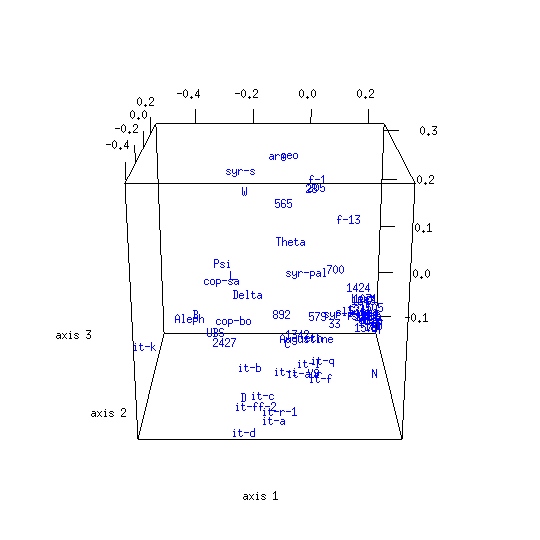
The galactic imagery Eldon J. Epp uses to describe text-types seems apt for the clusters evident in this analysis result:
A text-type is not a closely concentrated entity with rigid boundaries, but it is more like a galaxy — with a compact nucleus and additional but less closely related members which range out from the nucleus toward the perimeter. An obvious problem is how to determine when the outer limits of those more remote, accompanying members have been reached for one text-type and where the next begins.[13]
A term such as group, cluster, or nucleus might be used to describe a local maximum in the density of objects within a CMDS map. A line which joins two items might be called a trajectory, and a region between groups where there is a higher than usual concentration of witnesses might be called a stream or corridor.[14]
CMDS analysis of the control distance matrix produces the following result:
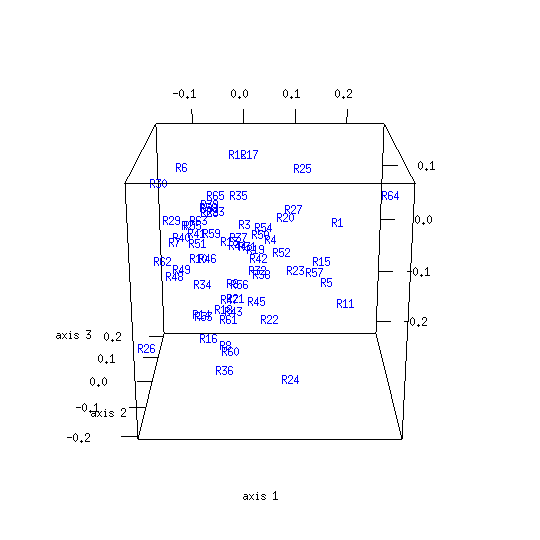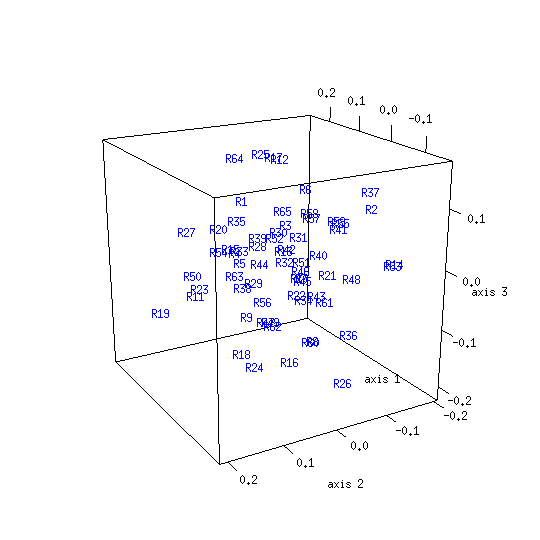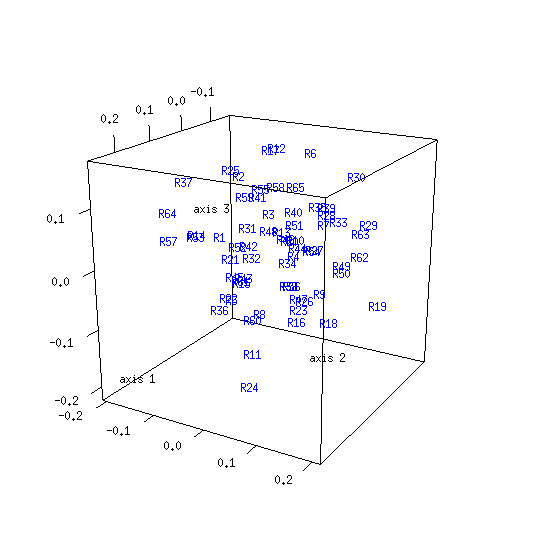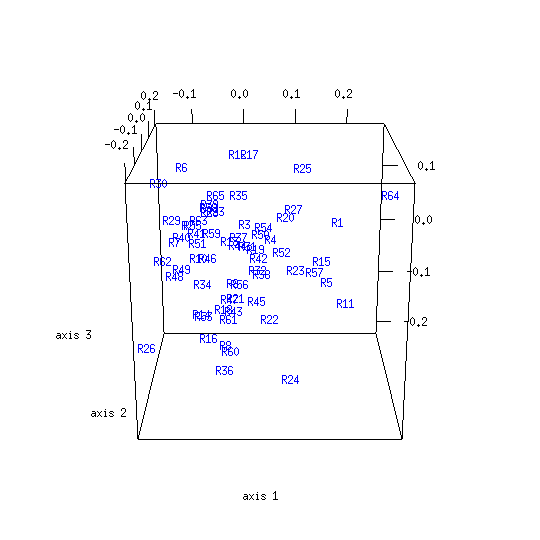
Any appearance of clustering in the control map is illusory: its objects are by definition unrelated, having been randomly generated. There are various differences between the model and control maps. The model map has an irregular shape while the control map is globular. Another difference relates to the respective map diameters: the volume enclosed by map axes is greater for the model than the control. This indicates that dispersion among New Testament texts is greater than would be expected if those texts resulted from random selection among alternative readings. Yet another difference is the proportion of variance figures for the model and control maps, which are respectively 0.51 and 0.16. The dimensionality of the New Testament distance data is lower than for the control data, making it easier to squeeze into only three dimensions.
Divisive clustering begins with a single cluster and ends with individual objects. The R program documentation describes the clustering algorithm as follows:[15]
At each stage, the cluster with the largest diameter is selected. (The diameter of a cluster is the largest dissimilarity between any two of its observations.) To divide the selected cluster, the algorithm first looks for its most disparate observation (i.e., which has the largest average dissimilarity to the other observations of the selected cluster). This observation initiates the "splinter group". In subsequent steps, the algorithm reassigns observations that are closer to the "splinter group" than to the "old party". The result is a division of the selected cluster into two new clusters.
This type of analysis produces a dendrogram which shows the “heights” at which clusters divide into sub-clusters. A divisive coefficient which measures the amount of clustering is presented as well. The value of this coefficient ranges from zero to one with larger values indicating a greater degree of clustering. A DC dendrogram does not necessarily reflect the family tree of objects in the underlying data set. Instead, it merely shows a reasonable way to progressively subdivide an all-encompassing cluster until every sub-cluster is comprised of a single object.[16]
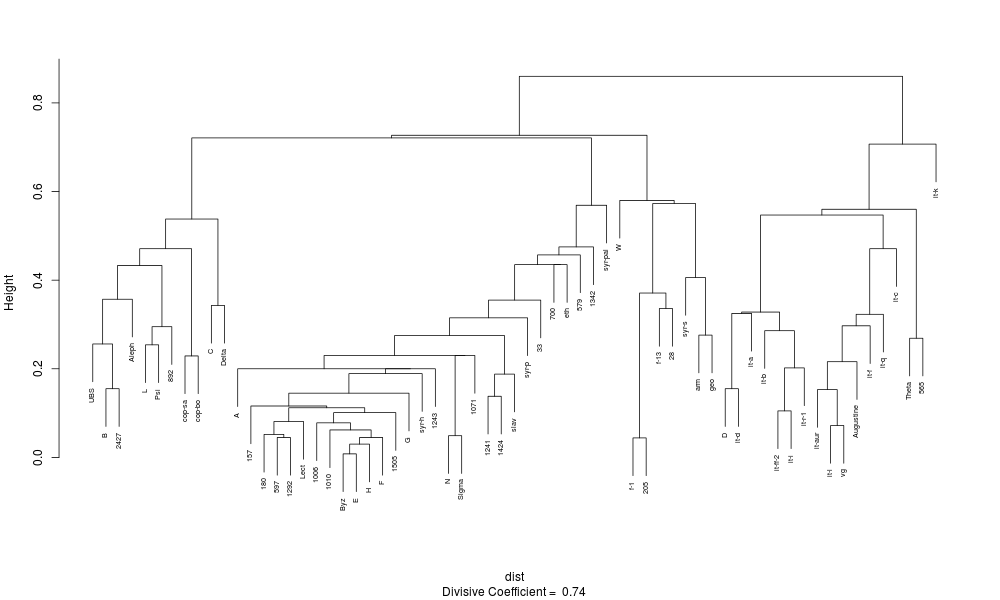
The vocabulary of tree structures is useful when discussing DC dendrograms. A branching point is called a node, each structure which descends from a node is called a branch, and terminals are called leaves. The dendrograms produced by analysing New Testament data have a self-similar character where, apart from scale, smaller parts have the same appearance as larger parts. Each branch contains its own sub-branches, unless terminated by leaves (i.e. individual witnesses).
A partition based on a DC dendrogram is obtained by means of a horizontal line which cuts across the dendrogram at some height to produce a set of separate branches. One possible height to cut a DC dendrogram is the upper critical limit of distances. Such a large distance is seldom encountered among unrelated objects. Cutting at the upper critical limit produces the following partition of the model data set.[17]
Table 5. DC partition (Mark, UBS4, upper critical limit)
| Group no. | Members |
|---|---|
| 1 | UBS Aleph B C L Delta Psi 892 2427 cop-sa cop-bo |
| 2 | A 33 157 180 579 597 700 1006 1010 1071 1241 1243 1292 1342 1424 1505 Byz E F G H N Sigma Lect syr-p syr-h eth slav |
| 3 | D Theta 565 it-a it-aur it-b it-c it-d it-f it-ff-2 it-i it-l it-q it-r-1 vg Augustine |
| 4 | W |
| 5 | f-1 f-13 28 205 |
| 6 | it-k |
| 7 | syr-pal |
| 8 | syr-s arm geo |
Performing DC analysis on the control distance matrix produces this dendrogram:
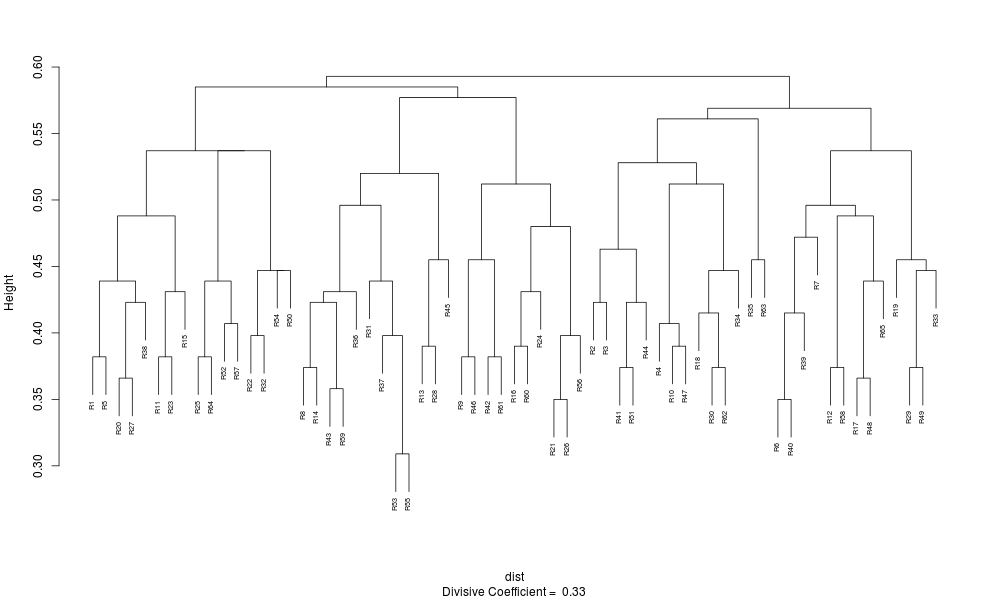
The model and control dendrograms seem quite similar at first glance although there are important differences: nearly all of the branching heights in the control dendrogram are in the normal range [0.374, 0.553], and the divisive coefficient for the model (0.74) is much larger than for the control (0.33).
The objects in the control can be grouped even though it is pointless to do so: if nearly all distances between objects fall within the normal range then partitioning may well be futile. In the present case, group sizes are more uniform for the control than model although there is no reason why a data set with actual groups cannot have uniform group sizes.
Table 6. DC partition (Mark, UBS4, control, upper critical limit)
| Group no. | Members |
|---|---|
| 1 | R1 R5 R11 R15 R20 R22 R23 R25 R27 R32 R38 R50 R52 R54 R57 R64 |
| 2 | R2 R3 R4 R10 R18 R30 R34 R41 R44 R47 R51 R62 |
| 3 | R6 R7 R12 R17 R19 R29 R33 R39 R40 R48 R49 R58 R65 |
| 4 | R8 R13 R14 R28 R31 R36 R37 R43 R45 R53 R55 R59 |
| 5 | R9 R16 R21 R24 R26 R42 R46 R56 R60 R61 |
| 6 | R35 R63 |
Neighbour joining (NJ) is an iterative process that begins with a starlike tree. A pair of neighbours is chosen at every step, being that pair of objects which gives the smallest sum of branch lengths. A node is then inserted between this pair, which node is regarded as a single object for subsequent steps. The procedure seeks to find the minimum-evolution tree, being that tree which most economically accounts for the observed set of distances between objects. While the method “produces a unique final tree under the principle of minimum evolution,” it does not always produce the minimum-evolution tree. However, computer simulations show that it “is quite efficient in obtaining the correct tree topology.”[18]
As with DC dendrograms, the vocabulary of tree structures is useful for discussing NJ analysis results. The NJ procedure produces an unrooted tree, meaning that any node or terminal in the result could be closest to the common ancestor of the entire tree.
Applying the NJ procedure to the model distance matrix produces a tree whose branches correspond to clusters seen in the CMDS and DC results obtained from the same distance matrix:[19]
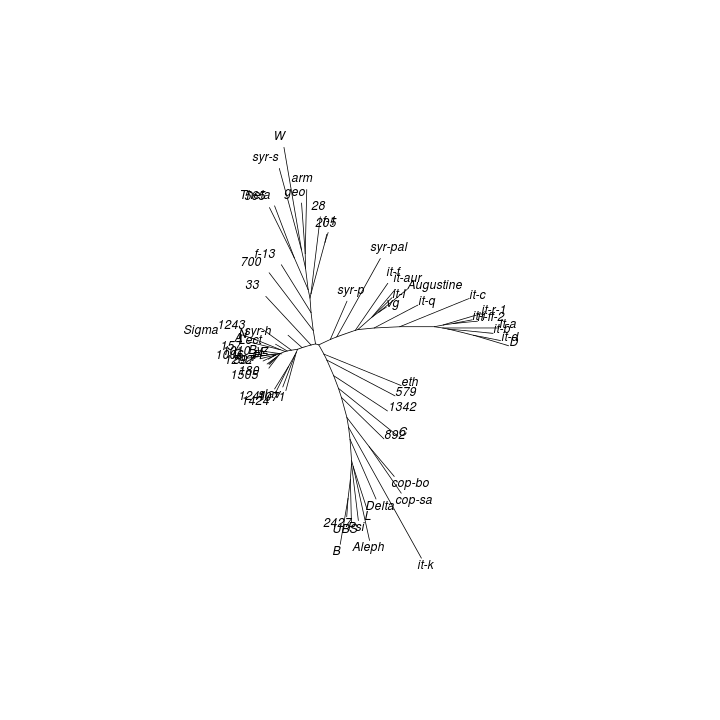
The tree obtained from the control distance matrix retains the NJ algorithm's initial starlike structure. This shows what kind of topology (i.e. shape) to expect for an NJ result derived from a data set comprised of unrelated objects. The marked difference from the model result is another indication that clustering exists among texts of Mark's Gospel.
Partitioning around medoids (PAM) builds clusters around representative objects called medoids. The program documentation provides this description:[20]
The ‘pam’-algorithm is based on the search for ‘k’ representative objects or medoids among the observations of the dataset. These observations should represent the structure of the data. After finding a set of ‘k’ medoids, ‘k’ clusters are constructed by assigning each observation to the nearest medoid. The goal is to find ‘k’ representative objects which minimize the sum of the dissimilarities of the observations to their closest representative object.
PAM analysis can be used to divide a data set into any number of clusters between two and the number of cases in the data set. The standard procedure in this study will be to partition data sets into two, three, four, five, and twelve clusters. The progression from two to five shows which groups separate first, while the twelve-way partition is useful for revealing core group members.[21]
Table 7. PAM (Mark, UBS4)
| No. | Groups with their medoids in [brackets] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Theta 2427 arm 565 it-aur L Augustine geo it-l it-q vg it-f syr-pal eth | |||||||||||
| 3 |
|
C syr-s arm vg | |||||||||||
| 4 |
|
syr-pal C W it-q Theta it-c eth | |||||||||||
| 5 |
|
eth 892 | |||||||||||
| 12 |
|
W it-k | 892 eth it-c L |
Brackets mark the medoid of each group. A medoid has the minimum mean distance to other group members and is the most central one for groups of three or more items. For two member groups, the PAM algorithm chooses one as the medoid.
Note
This study uses the bracketed medoid identifier as a label for the associated group. For example, [vg] refers to the first group in the above two-way partition.
A singleton is a solitary item which forms its own group. It is isolated, not having any close relatives within the data set. Singletons are listed under a separate heading, and the medoid of a singleton group is the sole member itself. The total number of groups in a partition equals the sum of numbers of singletons and multiple member groups.
Not all members of a group need be a good fit. PAM analysis calculates a statistic called the silhouette width for each object in the data set being partitioned into a chosen number of groups. Its value ranges from +1 to -1: the closer it is to +1, the better the associated case fits into its assigned group; by contrast, the closer the statistic is to -1, the worse the fit. Like hammering square pegs into round holes (or vice versa), negative silhouette widths indicate that the affected cases are not well suited to their assigned places. The last column in the table lists witnesses with negative silhouette widths, putting those with the most negative values last. The worst classified witnesses lie farthest to the right in such a list. A poor fit may indicate that a witness has a mixed text or that the chosen number of groups is too small for a text to be grouped with like texts alone.
As a data set is partitioned into larger numbers of groups, parent groups tend to spawn child groups while themselves contracting into narrower, more coherent groups. Group [Byz] is an example: as the same data set is partitioned into more and more groups, this group contributes items to various other groups while retaining a core membership. Partitioning a data set into a large number of groups reveals coherent cores comprised of close confederates.
Adding the partition's number of groups to the group label produces a more specific identifier. For example, [Byz] (3) refers to the group with medoid Byz in a three-way partition while [Byz] (12) refers to the group with medoid Byz in a twelve-way partition. Corresponding groups such as [Byz] (3) and [Byz] (12) are often produced when the same data set is divided into different numbers of parts. However, the medoids of such groups are not necessarily the same. Adding or subtracting even a single member can cause the medoid of a group to change. Consequently, correspondence must be established on the basis of shared membership, not common medoids. If groups from different partitions have the same core membership but differing medoids then descendant groups can be labelled by chaining the respective medoids together. To give an example from the table above, [Psi] (3) and [B] (5) share members but their medoids differ. One might label the subgroup as [Psi-B] (5) to indicate the connection with the supergroup from which its members are drawn.
Some numbers of groups are more suitable than others. Plotting a statistic called the mean silhouette width against each possible number of groups indicates which numbers of groups are more natural for the data set. The plot for the model data set indicates that three, six, eleven, and twenty-four are among the more preferable numbers of groups.[22]
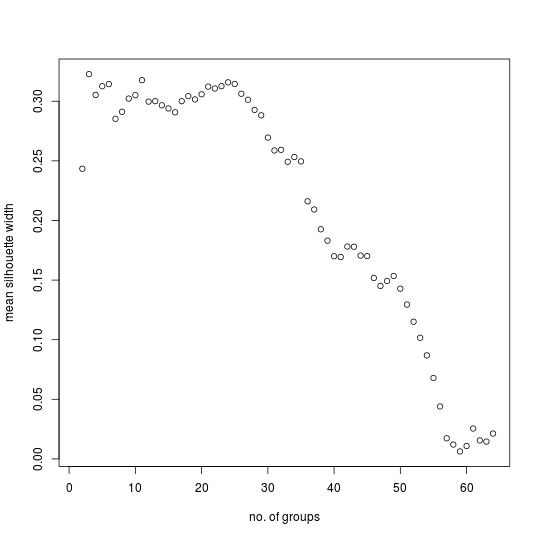
The MSW plot for the control data set also has a number of peaks even though that data set has no actual groups.
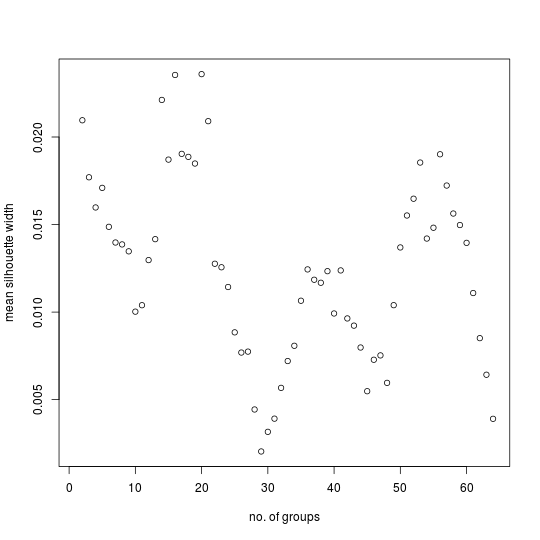
Comparing the model and control MSW plots reveals a great difference in the respective magnitudes of the MSW statistic. While the control data set is randomly generated and consequently contains no actual groups, there is nevertheless random clustering which accounts for the peaks seen in the associated MSW plot. The MSW plot for the control data set establishes a noise level: peaks with such small magnitudes are worthless as indicators of grouping.
The readings of a particular text can be subtracted to mask its effect on a data matrix. This is useful in cases where the text in question is thought to contribute readings to other texts. One example is the Byzantine text, which is a component of many “mixed” texts. If the influence of such a text is removed from a data matrix then what remains can be analysed to see how other texts relate in its absence.
Subtraction is achieved by selecting a text to eliminate then replacing its readings
with NA wherever they occur in a data matrix. A script called mask.R performs the task to produce a data matrix in
which all traces of the subtracted text are eliminated.
PAM (or a similar technique) can be used to identify texts that have a claim to represent their respective clusters. Once medoids are identified, they can be used to produce a corresponding series of masked data matrices in which the respective texts are eliminated. Such a series is given in the UBS4 data matrices of Mark, above.
This section presents results obtained by analysing the data sets referenced above using the methods described in the preceding section. The results are given in three parts:
CMDS, DC, and NJ results for all data sets
PAM results for selected data sets
ranked distances for patristic data sets.
PAM results are presented for a series of data sets selected for their broad coverage of witnesses and variation sites in respective sections of the New Testament. For patristic data sets, ranked distance is the preferred analysis mode.
Table 8. CMDS, DC, and NJ
| Section | Source | CMDS | DC | NJ |
|---|---|---|---|---|
| Matthew | Brooks | → | → | → |
| CB | → | → | → | |
| Cosaert | → | → | → | |
| Ehrman | → | → | → | |
| INTF-Parallel | → | → | → | |
| Racine | → | → | → | |
| UBS2 | → | → | → | |
| UBS2 (A) | → | → | → | |
| UBS4 | → | → | → | |
| Wasserman | → | → | → | |
| Mark | CB | → | → | → |
| Cosaert | → | → | → | |
| Hurtado (Mk 1) | → | → | → | |
| Hurtado (Mk 2) | → | → | → | |
| Hurtado (Mk 3) | → | → | → | |
| Hurtado (Mk 4) | → | → | → | |
| Hurtado (Mk 5) | → | → | → | |
| Hurtado (Mk 6) | → | → | → | |
| Hurtado (Mk 7) | → | → | → | |
| Hurtado (Mk 8) | → | → | → | |
| Hurtado (Mk 9) | → | → | → | |
| Hurtado (Mk 10) | → | → | → | |
| Hurtado (Mk 11) | → | → | → | |
| Hurtado (Mk 12) | → | → | → | |
| Hurtado (Mk 13) | → | → | → | |
| Hurtado (Mk 14) | → | → | → | |
| Hurtado (Mk 15+) | → | → | → | |
| Hurtado (P45) | → | → | → | |
| Mullen | → | → | → | |
| Mullen (P45) | → | → | → | |
| INTF-Parallel | → | → | → | |
| UBS2 (C) | → | → | → | |
| UBS4 | → | → | → | |
| UBS4 (control) | → | → | → | |
| UBS4 (it-e) | → | → | → | |
| UBS4 (it-k) | → | → | → | |
| UBS4 (Jerome) | → | → | → | |
| UBS4 (non-B) | → | → | → | |
| UBS4 (non-Byz) | → | → | → | |
| UBS4 (non-f-1) | → | → | → | |
| UBS4 (non-it-ff-2) | → | → | → | |
| UBS4 (non-vg) | → | → | → | |
| UBS4 (Origen) | → | → | → | |
| UBS4 (P45) | → | → | → | |
| Wasserman | → | → | → | |
| Luke | Brooks | → | → | → |
| CB | → | → | → | |
| Cosaert | → | → | → | |
| Fee (Lk 10) | → | → | → | |
| INTF-Parallel | → | → | → | |
| UBS2 | → | → | → | |
| Wasserman | → | → | → | |
| John | Brooks (C) | → | → | → |
| Brooks (it-j) | → | → | → | |
| CB | → | → | → | |
| Cosaert | → | → | → | |
| Cunningham | → | → | → | |
| EFH | → | → | → | |
| Fee (Jn 1-8) | → | → | → | |
| Fee (Jn 1-8, corr.) | → | → | → | |
| Fee (Jn 4) | → | → | → | |
| Fee (Jn 4, corr.) | → | → | → | |
| Fee (Jn 4, pat.) | → | → | → | |
| Fee (Jn 4, pat., corr.) | → | → | → | |
| Fee (Jn 9) | → | → | → | |
| Fee (Jn 9, corr.) | → | → | → | |
| INTF-Parallel | → | → | → | |
| UBS2 (Aleph) | → | → | → | |
| Wasserman | → | → | → | |
| PA | Wasserman | → | → | → |
| Acts | Donker | → | → | → |
| Donker (Acts 1-12) | → | → | → | |
| Donker (Acts 13-28) | → | → | → | |
| Osburn | → | → | → | |
| UBS2 (Aleph) | → | → | → | |
| UBS2 (P45) | → | → | → | |
| General Letters | Donker | → | → | → |
| James | INTF-General | → | → | → |
| 1 Peter | INTF-General | → | → | → |
| UBS4 | → | → | → | |
| 2 Peter | INTF-General | → | → | → |
| 1 John | INTF-General | → | → | → |
| Richards | → | → | → | |
| UBS4 | → | → | → | |
| 2 John | INTF-General | → | → | → |
| 3 John | INTF-General | → | → | → |
| Jude | INTF-General | → | → | → |
| Paul's Letters | Brooks | → | → | → |
| Cunningham | → | → | → | |
| Donker | → | → | → | |
| Osburn | → | → | → | |
| Romans | Donker | → | → | → |
| 1 Corinthians | Donker | → | → | → |
| 2 Corinthians | UBS4 | → | → | → |
| 2 Cor. - Titus | Donker | → | → | → |
| Hebrews | Donker | → | → | → |
| UBS4 | → | → | → | |
| UBS4 (B) | → | → | → | |
| Revelation | UBS4 | → | → | → |
PAM results for selected data sets are presented below, arranged according to major divisions of the New Testament. The chosen data sets have a relatively broad coverage of witnesses and variation sites. Group medoids are marked by brackets (e.g. [033]). Results for each data set are presented as partitions into two, three, four, five, and twelve groups: the progression through two to five reveals the sequence of group emergence; the division into twelve (a somewhat arbitrary number) shows which groups survive a many-way division. (Such groups are aptly described as “coherent.”)
Table 9. PAM (Matt, INTF-Parallel)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
33 05 01 892 A 03 | ||||||||||||
| 3 |
|
209 118 205 019 79 372 33 1 700 05 2737 01 740 1593 04 732 792 1823 032 043 1009 2766 1446 A 892 735 174 807 2726 827 2786 011 1661 61 2372 037 1342 042 1457 829 1344 1071 1279 22 1328 1093 348 1330 1579 1334 013 1528 4 1780 18 791 1451 1331 1339 1253 03 1692 35 1555 131 222 1273 517 968 176 1502 1340 150 1329 0233 191 021 1333 752 07 031 036 034 1345 1338 1602 1346 09 | ||||||||||||
| 4 |
|
1582 209 2680 118 205 019 372 79 33 1 700 1424 01 05 2737 04 1593 740 A 032 1823 732 792 043 892 2766 1446 1009 174 735 1661 827 011 807 2786 037 2372 22 042 1457 1328 1342 1344 1071 03 1330 1093 1334 013 18 1780 791 4 1451 1339 1331 1253 35 1692 1555 968 517 176 1273 131 222 1340 1502 0233 021 150 1329 191 1333 07 752 031 036 1345 034 1346 1338 1602 09 | ||||||||||||
| 5 |
|
2680 79 1823 032 732 372 022 011 019 1582 740 700 043 2737 1334 1328 18 04 1009 735 013 1339 1424 174 792 037 1342 827 2766 1457 1330 1446 1344 35 1071 2372 2786 1661 22 042 1780 131 807 791 1093 1340 1692 1451 150 031 968 4 1331 1333 07 1555 1329 021 752 176 1273 1253 222 517 034 1502 0233 191 036 1345 1346 09 1338 1602 1 038 | ||||||||||||
| 12 |
|
05 | 740 1336 1330 273 33 3 79 1326 792 979 013 130 827 752 1093 807 1344 1780 1506 0211 1347 1342 2542 022 047 2372 31 4 030 1253 28 735 892 019 1230 1333 579 1341 045 032 131 1334 043 011 1446 1343 2680 233 851 1692 1273 1457 1823 1296 09 1555 150 1574 1071 2546 157 1348 1338 18 1339 031 191 036 2786 22 174 1110 042 037 791 1328 1340 35 07 028 04 176 038 700 222 1331 1345 0233 1329 034 021 1502 |
Table 10. PAM (Matt, UBS2)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Eusebius it-h f-1 Cyril cop it-q | ||||||||||
| 3 |
|
syr-pal it-k 33 Cyprian Jerome Eusebius Origen it-q Cyril | ||||||||||
| 4 |
|
it-k Origen syr-pal Cyprian f-1 33 Jerome Eusebius it-q Cyril | ||||||||||
| 5 |
|
it-g-1 it-k syr-s Origen syr-pal Jerome f-1 33 it-c Ambrose Eusebius it-q Cyril | ||||||||||
| 12 |
|
it-k Diatessaron Eusebius | 33 Cyprian Origen syr-pal it-q 700 892 |
Table 11. PAM (Matt, UBS2, A)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Cyril f-1 cop it-q | |||||||||
| 3 |
|
f-1 syr-pal 33 Jerome Eusebius Origen it-q Cyril | |||||||||
| 4 |
|
Origen Jerome syr-pal 33 f-1 Eusebius it-q Cyril | |||||||||
| 5 |
|
syr-s Jerome it-ff-2 syr-pal 33 Origen f-1 Eusebius Ambrose it-q Cyril | |||||||||
| 12 |
|
syr-s syr-pal Diatessaron Eusebius | 33 it-q 700 892 |
Table 12. PAM (Matt, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
syr-s f-1 | ||||||||||||
| 3 |
|
syr-s it-k cop-meg it-h f-1 | ||||||||||||
| 4 |
|
it-q syr-c syr-s arm D cop-meg it-d it-k f-13 eth C f-1 it-h Delta Sigma syr-h 1241 | ||||||||||||
| 5 |
|
arm D it-g-1 f-1 eth f-13 C Chromatius it-d it-k cop-meg syr-c Delta Sigma syr-h 1241 | ||||||||||||
| 12 |
|
it-k | cop-sa it-g-1 syr-pal 892 syr-p Theta eth 33 Chromatius 700 1424 Chrysostom Delta Sigma syr-h 1241 28 1010 |
Table 13. PAM (Mark, INTF-Parallel)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
05 | |||||||||||
| 3 |
|
05 032 | |||||||||||
| 4 |
|
05 | |||||||||||
| 5 |
|
05 565 | |||||||||||
| 12 |
|
032 05 | 1457 047 1337 1326 1330 176 79 700 1329 2737 1347 1345 1253 372 1574 1692 1009 1823 1338 0211 713 1344 042 157 2546 1451 2766 2680 1230 968 791 31 043 1071 1336 130 1502 233 1012 150 030 752 1340 021 034 |
Table 14. PAM (Mark, UBS2, C)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Aug | ||||||||||
| 3 |
|
C Orig syr-s 33 | ||||||||||
| 4 |
|
565 C arm syr-s it-c it-f syr-pal Orig geo it-q 33 | ||||||||||
| 5 |
|
W 28 syr-pal 33 | ||||||||||
| 12 |
|
W Orig syr-s | B 1241 cop Psi 1216 1546 1365 2174 1195 Dia syr-pal 1079 33 1646 |
Table 15. PAM (Mark, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Theta 2427 arm 565 it-aur L Augustine geo it-l it-q vg it-f syr-pal eth | |||||||||||
| 3 |
|
C syr-s arm vg | |||||||||||
| 4 |
|
syr-pal C W it-q Theta it-c eth | |||||||||||
| 5 |
|
eth 892 | |||||||||||
| 12 |
|
W it-k | 892 eth it-c L |
Table 16. PAM (Mark, UBS4, it-e)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
2427 cop-bo arm 565 Theta L it-aur it-q geo it-l vg it-f eth | |||||||||||
| 3 |
|
it-q Theta 565 W 892 | |||||||||||
| 4 |
|
892 | |||||||||||
| 5 |
|
Theta eth 892 | |||||||||||
| 12 |
|
W it-e | syr-s eth it-c 892 L |
Table 17. PAM (Mark, UBS4, it-k)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Theta 2427 arm 565 it-aur L Augustine geo it-l it-q vg it-f syr-pal eth | |||||||||||
| 3 |
|
C syr-s arm vg | |||||||||||
| 4 |
|
syr-pal C W it-q Theta it-c eth | |||||||||||
| 5 |
|
eth 892 | |||||||||||
| 12 |
|
W it-k | 892 eth it-c L |
Table 18. PAM (Mark, UBS4, Jerome)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
W L Theta Jerome it-aur 565 it-l vg it-f eth | ||||||||
| 3 |
|
W Jerome 565 it-f 892 eth | ||||||||
| 4 |
|
565 it-c 892 eth | ||||||||
| 5 |
|
it-c 892 Theta eth | ||||||||
| 12 |
|
W 579 1342 it-c Jerome |
Table 19. PAM (Mark, UBS4, non-B)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
f-1 205 eth L syr-p | ||||||||||
| 3 |
|
W it-q cop-sa it-c eth L syr-s syr-p | ||||||||||
| 4 |
|
28 eth it-q it-c cop-sa syr-p L it-i | ||||||||||
| 5 |
|
it-c syr-p 28 579 cop-sa it-i | ||||||||||
| 12 |
|
C W cop-sa | f-13 892 1424 syr-p syr-s it-a 700 slav 28 1241 |
Table 20. PAM (Mark, UBS4, non-Byz)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
W syr-s geo 205 f-1 | |||||||||||
| 3 |
|
||||||||||||
| 4 |
|
||||||||||||
| 5 |
|
892 | |||||||||||
| 12 |
|
W 579 | 28 892 |
Table 21. PAM (Mark, UBS4, non-f-1)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
it-q 892 vg W it-l it-f syr-p | ||||||||
| 3 |
|
it-aur 579 it-c eth vg | ||||||||
| 4 |
|
arm 579 eth it-c vg | ||||||||
| 5 |
|
arm C cop-sa 579 1342 eth 892 vg it-c Delta | ||||||||
| 12 |
|
W 28 579 it-c arm | it-q cop-sa 892 33 1342 eth L |
Table 22. PAM (Mark, UBS4, non-it-ff-2)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
arm geo 565 579 C Theta 892 it-c 33 eth | ||||||||
| 3 |
|
it-q it-aur it-l Theta arm geo syr-s 579 565 892 it-f vg syr-p C eth 33 1342 | ||||||||
| 4 |
|
28 579 vg syr-p 892 C eth 1342 cop-sa | ||||||||
| 5 |
|
D | 28 892 eth 1342 C cop-sa | |||||||
| 12 |
|
C D W Delta it-c | 892 700 eth 33 1342 |
Table 23. PAM (Mark, UBS4, non-vg)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
579 C Theta geo | |||||||||
| 3 |
|
565 W Theta | |||||||||
| 4 |
|
f-13 579 cop-sa eth | |||||||||
| 5 |
|
cop-sa 579 eth f-13 | |||||||||
| 12 |
|
W 579 it-c it-q | cop-sa f-13 L |
Table 24. PAM (Mark, UBS4, Origen)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
2427 Theta arm 565 L it-aur Origen geo it-q it-l vg it-f eth | ||||||||||
| 3 |
|
W syr-s it-aur 892 arm vg | ||||||||||
| 4 |
|
892 W | ||||||||||
| 5 |
|
it-q eth 892 W | ||||||||||
| 12 |
|
W it-c syr-s | eth |
Table 25. PAM (Mark, UBS4, P45)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
Aleph | |||||||||
| 3 |
|
1342 892 | |||||||||
| 4 |
|
||||||||||
| 5 |
|
28 it-c | |||||||||
| 12 |
|
P45 W 28 arm | 579 Sigma 1342 eth syr-p syr-h |
Table 26. PAM (Luke, INTF-Parallel)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
579 | |||||||||||
| 3 |
|
33 04 892 | |||||||||||
| 4 |
|
05 33 157 04 892 | |||||||||||
| 5 |
|
1012 1451 968 827 033 05 1692 33 044 222 1506 1342 735 79 863 1253 1230 1574 157 024 1337 700 1457 2766 04 1446 1330 1661 954 2680 021 807 032 713 1346 1071 892 1093 1009 041 233 1336 61 851 1338 017 191 2737 1329 979 372 28 1334 565 18 1339 1328 35 1421 31 1333 1602 1502 1823 427 150 174 1345 | |||||||||||
| 12 |
|
05 740 | 863 024 1337 1574 1230 1241 1692 044 1253 892 807 1342 2680 191 233 1093 954 851 1661 979 1336 1009 713 61 157 28 1338 1329 1339 372 2737 33 1330 1334 18 1502 31 1328 35 427 565 1333 2766 1602 1823 021 150 792 1071 222 174 033 79 700 04 032 1345 040 038 |
Table 27. PAM (Luke, UBS2)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
syr-s Marcion Origen B it-aur Xi | |||||||||||
| 3 |
|
syr-s Marcion Cyril eth Origen it-aur syr-pal Eusebius | |||||||||||
| 4 |
|
Cyril it-e Marcion syr-s Origen it-aur Augustine eth syr-pal Tertullian Eusebius | |||||||||||
| 5 |
|
it-r-1 Cyril syr-s Marcion Origen it-e eth syr-pal Eusebius | |||||||||||
| 12 |
|
eth Ambrose | Psi Eusebius A X Lect 2148 700 Augustine Cyril 1009 K Irenaeus Origen it-c syr-pal Pi |
Table 28. PAM (John, INTF-Parallel)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
1071 2786 02 69 1446 038 | |||||||||||
| 3 |
|
1071 2786 02 1446 038 | |||||||||||
| 4 |
|
01 1346 579 038 2411 P66 041 019 2786 02 1071 044 892 33 | |||||||||||
| 5 |
|
1230 1253 01 579 041 2411 038 P66 1071 019 02 2786 1457 044 892 33 | |||||||||||
| 12 |
|
01 05 | 191 1331 1692 851 1343 740 273 979 863 791 22 1604 1502 1273 1241 124 017 |
Table 29. PAM (John, UBS2, Aleph)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
syr-s arm geo Cyril X cop | ||||||||||||
| 3 |
|
syr-c Tertullian it-aur Diatessaron it-r-1 Hilary Cyprian it-f eth geo 33 Cyril it-q vg syr-pal Eusebius X Chrysostom cop goth Theodoret | ||||||||||||
| 4 |
|
arm Cyprian Diatessaron it-f Tertullian 33 geo syr-c syr-p vg eth it-q Cyril syr-pal X Eusebius Chrysostom 1230 cop goth 1253 Pi 1646 2174 Theodoret | ||||||||||||
| 5 |
|
arm syr-c Cyprian syr-s it-f vg Diatessaron 33 geo Tertullian syr-p eth Cyril it-q X syr-pal Eusebius Chrysostom 1230 cop goth 1253 Pi 1646 2174 Theodoret | ||||||||||||
| 12 |
|
eth | 1071 1546 1242 Aleph X it-b 565 K Diatessaron 1010 Nonnus 1230 892 Origen f-13 syr-p Cyril Lect Tertullian Chrysostom syr-c 1365 it-q 1344 1009 Eusebius cop it-l it-r-1 it-ff-2 goth 1253 Pi |
Table 30. PAM (Acts, Donker)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||
|---|---|---|---|---|---|---|---|
| 2 |
|
||||||
| 3 |
|
||||||
| 4 |
|
D | |||||
| 5 |
|
D | 044 81 B | ||||
| 12 |
|
Ath B D E 044 81 383 614 | 01 |
Table 31. PAM (Acts, UBS2, Aleph)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
eth it-d it-gig 1739 Origen Lucifer 181 | ||||||||||
| 3 |
|
eth it-l 1739 Lucifer Origen 181 | ||||||||||
| 4 |
|
it-r it-l E eth it-e Lucifer 81 C 33 Origen | ||||||||||
| 5 |
|
syr-p it-l it-r syr-h it-ar 81 Lucifer E Origen 614 2412 Psi C 33 | ||||||||||
| 12 |
|
it-p cop-sa eth | syr-h 33 Lucifer Origen C it-r cop-bo Psi |
Table 32. PAM (Acts, UBS2, P45)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
it-d eth it-gig 1739 181 Lucifer Origen P45 Aleph-c | ||||||||||||
| 3 |
|
it-gig eth 1739 Lucifer 181 Origen P45 Aleph-c | ||||||||||||
| 4 |
|
it-gig E eth it-e 81 C Lucifer P45 Origen 33 | ||||||||||||
| 5 |
|
syr-p it-e it-gig syr-h C it-ar 81 Lucifer E P45 614 2412 arm Psi 33 | ||||||||||||
| 12 |
|
it-p | syr-h Origen P45 cop-bo 33 Psi it-r C |
Table 33. PAM (James, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
2147 2652 | ||||||||||||
| 3 |
|
2805 2147 2492 2652 1852 | ||||||||||||
| 4 |
|
2805 2147 2652 02 81 1852 2344 | ||||||||||||
| 5 |
|
1501 665 319 1729 1850 254 61 2523 43 1359 1874 18 676 2544 1609 378 2423 056 1127 35 1066 6 218 1367 2080 621 1390 93 181 38 2774 631 431 2464 456 808 0142 2147 607 623 1845 5 642 2805 643 365 1875 629 398 1524 1 88 1509 876 312 049 2243 1853 2180 1765 2652 2494 424 1832 81 02 1852 2492 2344 69 018 468 | ||||||||||||
| 12 |
|
631 | 2180 181 1367 1875 254 621 1501 1524 81 643 02 424 2544 629 049 88 5 1850 1 1751 398 365 623 915 04 1842 459 2674 2423 104 431 1848 1874 326 1609 61 1735 467 676 1837 607 322 456 2242 1729 2344 2080 1827 6 617 2774 323 252 1390 38 330 1251 1845 312 2492 442 999 18 378 996 43 2523 69 1509 1661 1852 1853 321 020 93 35 2718 319 665 018 468 197 1292 |
Table 34. PAM (1 Peter, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
945 2541 2718 1739 5 04 1852 2344 621 044 1243 33 81 P72 1067 1735 436 1409 2464 02 1875 1729 | |||||||||
| 3 |
|
1563 1359 945 218 2718 1739 1718 ECM 1852 04 044 1243 01 621 P72 2374 2805 5 2464 33 2344 1875 1735 81 1729 623 02 | |||||||||
| 4 |
|
2718 945 1739 1832 ECM 876 04 1175 044 1243 1127 01 P72 2374 621 5 2805 1852 378 1448 2464 33 2344 1735 81 1875 1729 2147 623 02 2652 1890 1831 1505 2138 1292 1611 630 | |||||||||
| 5 |
|
254 945 424 2423 459 629 1739 43 1881 321 1832 1838 607 1609 2186 1524 93 1595 69 94 ECM 876 915 2718 104 61 04 468 049 35 1842 1175 044 1270 400 307 1243 330 665 2544 2818 1297 01 P72 617 2243 1845 918 453 1837 020 1827 1661 431 88 326 365 6 996 2774 1 1678 1852 5 2805 1751 180 720 319 2492 621 378 1448 2464 33 1735 81 1875 2147 623 1127 02 2344 2652 1729 1890 1831 1505 642 808 2138 2374 1292 1611 218 630 | |||||||||
| 12 |
|
01 621 1175 2805 | 254 1524 307 1881 2818 629 453 918 2298 P72 1838 1661 915 94 1678 323 996 61 2718 88 180 398 720 69 2774 2492 1842 104 1609 1751 459 33 044 365 5 1448 1827 1735 81 1241 2186 400 1595 945 1845 1837 326 468 330 1848 04 1270 1852 467 43 18 1874 378 35 1297 049 2147 252 02 607 2344 665 1127 1501 181 442 321 1739 2652 025 2423 020 6 1243 93 1 319 617 623 2464 1890 ECM 1505 642 808 2374 2138 218 1292 1611 630 |
Table 35. PAM (1 Peter, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
UBS 2464 Aleph eth cop-bo 044 P | |||||||||
| 3 |
|
1505 044 geo 1292 2464 1735 | |||||||||
| 4 |
|
044 UBS 1852 geo 2464 1735 | |||||||||
| 5 |
|
81 P72 1852 044 A UBS geo 1735 2464 | |||||||||
| 12 |
|
Aleph 044 syr-p arm | 945 1175 1243 81 geo 1739 cop-sa 1881 eth 1735 |
Table 36. PAM (2 Peter, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
254 1524 378 1831 1490 2147 2652 | |||||||||||||
| 3 |
|
P72 04 2718 2805 1881 398 33 2344 378 1831 81 1490 720 1067 918 2818 436 307 ECM 1678 453 2541 1848 1661 467 996 1852 915 2147 2652 1890 | |||||||||||||
| 4 |
|
1751 1409 02 03 2298 2186 621 1881 2805 P72 33 398 1175 2344 442 01 1831 1243 1490 468 2718 81 025 1067 04 436 2541 1852 1848 1661 467 996 ECM 915 1890 2147 2652 | |||||||||||||
| 5 |
|
623 621 2186 1175 P72 1881 398 442 1243 2805 01 1831 1490 468 044 2718 025 1735 81 04 2344 33 02 1852 1848 1661 ECM 996 467 915 1890 2147 2652 | |||||||||||||
| 12 |
|
1175 1448 2186 43 1270 1751 180 61 2774 018 365 1837 2492 1595 1609 93 424 252 617 1243 01 1127 1875 621 468 1735 2718 025 04 398 442 642 02 33 81 ECM 1848 |
Table 37. PAM (1 John, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
1735 6 81 1844 1127 1524 1523 1678 2492 1718 453 720 2818 307 808 398 | |||||||||||||
| 3 |
|
6 81 378 2147 1844 1127 2492 1524 1523 1718 1678 720 2652 453 1448 1852 808 2818 307 398 | |||||||||||||
| 4 |
|
629 467 321 1881 2298 03 326 61 378 2147 1837 6 1067 2805 1844 1524 1523 2652 720 2492 436 2464 1852 81 1448 33 623 2541 1678 453 1409 2344 02 2818 5 307 398 | |||||||||||||
| 5 |
|
629 2544 468 467 01 03 326 04 2298 ECM 442 1846 61 254 1837 025 1881 2805 1067 2464 436 378 1852 33 1409 6 623 1448 2541 02 2344 1844 2186 81 5 1524 1523 2492 398 | |||||||||||||
| 12 |
|
04 442 025 1881 1842 1448 2186 6 1846 33 81 02 2344 2492 398 1852 |
Table 38. PAM (1 John, Richards)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
01 | |||||||||
| 3 |
|
01 | |||||||||
| 4 |
|
01 | |||||||||
| 5 |
|
01 2401 999 1898 1827 1874 1522 1243 1610 1799 | |||||||||
| 12 |
|
02 03 044 6 | 356 1872 020 69 876 1245 642 1738 38 TR 1829 1315 181 2401 999 1898 1827 1522 1874 1243 1610 1799 |
Table 39. PAM (1 John, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
syr-p 1243 Aleph 044 1881 | |||||||||||
| 3 |
|
P arm eth | |||||||||||
| 4 |
|
1611 cop-bo arm P cop-sa syr-p eth geo 2464 1292 | |||||||||||
| 5 |
|
arm P 2464 eth syr-h | |||||||||||
| 12 |
|
syr-p cop-sa | 1852 1881 eth |
Table 40. PAM (2 John, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
915 88 621 467 | ||||||||||||
| 3 |
|
1846 876 1832 6 | ||||||||||||
| 4 |
|
2138 1611 044 1505 400 01 1292 621 2243 1067 2805 467 2541 6 2147 | ||||||||||||
| 5 |
|
1524 467 2774 326 181 1661 1838 1735 94 6 1874 996 1837 1751 02 1 2374 1827 2718 617 | ||||||||||||
| 12 |
|
1836 81 1735 1661 2147 2652 181 02 2544 5 2805 996 1838 378 1874 94 621 623 467 1751 044 1 2718 1827 1852 617 048 915 |
Table 41. PAM (3 John, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
5 2774 623 6 93 431 915 88 | |||||||||||||
| 3 |
|
1718 1852 01 1297 2243 1846 5 2374 1595 720 044 1505 623 6 1838 1836 93 1661 431 94 915 88 | |||||||||||||
| 4 |
|
1409 1852 2374 720 1297 1846 5 1595 044 623 6 1838 94 1836 1661 93 431 88 915 | |||||||||||||
| 5 |
|
01 1845 1852 1409 5 044 1846 1270 6 623 94 1836 1661 1838 93 431 88 915 | |||||||||||||
| 12 |
|
459 044 02 5 1852 6 629 61 1837 623 93 81 1661 2774 1735 049 1501 1845 |
Table 42. PAM (Jude, INTF-General)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
6 1409 629 321 918 436 2818 1067 307 453 1678 431 2374 1875 1836 1127 | |||||||||||||
| 3 |
|
104 1409 61 436 6 1067 431 1875 2374 1836 1127 | |||||||||||||
| 4 |
|
69 2344 33 915 623 01 P72 1838 1359 1563 02 621 88 1718 323 81 1852 6 ECM 1243 1842 442 5 629 2243 1875 1067 467 61 431 2374 1836 | |||||||||||||
| 5 |
|
1409 1842 1846 621 720 915 1838 1241 1881 436 5 323 88 2147 326 2374 1067 2805 61 1735 2652 6 1243 2298 1844 1523 254 04 1448 431 2544 2243 1875 1852 1836 467 1127 020 1609 | |||||||||||||
| 12 |
|
254 1845 621 1523 81 945 0142 1751 2774 1837 1524 1409 1735 1846 2805 623 2544 326 1243 1448 61 436 5 2374 1067 04 020 431 1852 218 467 1609 1842 |
Table 43. PAM (Paul, Donker)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||
|---|---|---|---|---|---|---|---|
| 2 |
|
1739 Ath | |||||
| 3 |
|
||||||
| 4 |
|
P46 | B | ||||
| 5 |
|
Ath P46 | 01-c B | ||||
| 12 |
|
Ath P46 01 01-c B D 33 1739 | 049 L |
Table 44. PAM (Romans, Donker)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||
|---|---|---|---|---|---|---|---|
| 2 |
|
33 | |||||
| 3 |
|
||||||
| 4 |
|
B | 33 | ||||
| 5 |
|
Ath B | 33 | ||||
| 12 |
|
Ath 01-c A B K 33 104 1739 | P 876 |
Table 45. PAM (1 Corinthians, Donker)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||
|---|---|---|---|---|---|---|---|---|
| 2 |
|
A | ||||||
| 3 |
|
|||||||
| 4 |
|
A 33 1739 P46 | ||||||
| 5 |
|
Ath | B 33 P46 | |||||
| 12 |
|
Ath P46 A C D 33 1739 | 876 L |
Table 46. PAM (2 Corinthians, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
1175 81 D it-f G 1962 | ||||||||||||
| 3 |
|
1962 vg | ||||||||||||
| 4 |
|
P 2464 cop-bo 1881 vg | ||||||||||||
| 5 |
|
arm A eth | ||||||||||||
| 12 |
|
eth | 6 cop-bo 2200 263 it-b Ambrosiaster |
Table 47. PAM (Hebrews, Donker)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||
|---|---|---|---|---|---|---|
| 2 |
|
|||||
| 3 |
|
33 | ||||
| 4 |
|
D | ||||
| 5 |
|
D 1739 | ||||
| 12 |
|
Ath 01 01-c A D P 044 33 104 1739 |
Table 48. PAM (Hebrews, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
0150 slav 365 104 Psi 459 it-d 2127 | ||||||||||
| 3 |
|
UBS 104 365 0150 459 geo-1 1739 cop-bo Psi slav eth-TH 2127 eth-pp | ||||||||||
| 4 |
|
Aleph 104 cop-sa 6 0150 459 365 syr-h geo-1 Psi slav | ||||||||||
| 5 |
|
0150 cop-sa 459 syr-h 365 104 geo-1 Psi slav syr-p | ||||||||||
| 12 |
|
P46 D it-d | syr-p 1912 P A slav cop-sa cop-bo 436 263 365 |
Table 49. PAM (Hebrews, UBS4, B)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
1573 459 0150 2127 Psi it-d | |||||||||||
| 3 |
|
263 UBS geo-1 slav 0150 2127 Psi 1739 eth-TH cop-bo eth-pp | |||||||||||
| 4 |
|
geo-1 104 365 cop-bo 459 0150 1739 Psi eth-TH slav 2127 UBS eth-pp | |||||||||||
| 5 |
|
459 365 cop-sa 0150 6 geo-1 Psi UBS syr-h slav | |||||||||||
| 12 |
|
D it-d | arm A syr-p 1912 P cop-sa cop-bo slav 436 263 365 |
Table 50. PAM (Revelation, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
arm 2329 2344 2351 | |||||||
| 3 |
|
arm 2329 2351 2344 Primasius | |||||||
| 4 |
|
arm 2329 cop-bo 2053 syr-ph UBS C 2344 1611 Primasius 2351 | |||||||
| 5 |
|
cop-bo 2053 syr-ph UBS arm C 1611 Primasius 2344 | |||||||
| 12 |
|
Aleph 2344 syr-ph arm eth Primasius | 2329 2053 syr-h |
Ranked distance results are presented in tables devoted to individual Church Fathers. The lists include asterices to mark distances that are not statistically significant provided the number of well-defined variation sites per witness is known. (The numbers, if known, are found in a "counts" file associated with the relevant distance matrix.) Indications of statistical significance are not given when these numbers are not known.
Table 51. Athanasius
| Section | Ranked distances |
|---|---|
| Acts (Donker) | 81 (0.220); B (0.244); 1891 (0.244); A (0.267*); 044 (0.267*); 01 (0.289*); 630 (0.289*); 1175 (0.289*); 1704 (0.289*); 945 (0.311*); 1739 (0.311*); P74 (0.326*); P (0.341*); C (0.366*); H (0.400*); 1073 (0.400*); L (0.406*); 049 (0.422*); 1352 (0.422*); 383 (0.476*); E (0.489*); 614 (0.511*); D (0.611) |
| General Letters (Donker) | L (0.500*); 105 (0.500*); 201 (0.500*); 1739 (0.500*); A (0.583*); 044 (0.583*); 1022 (0.583*); 1424 (0.583*); 2423 (0.583*); 049 (0.667*); 323 (0.667*); 01 (0.750*); B (0.833) |
| Paul's Letters (Donker) | C (0.322); P (0.378*); A (0.387*); 33 (0.387*); 01-c (0.399*); 01 (0.405*); 1739 (0.417*); 104 (0.419*); L (0.443*); 223 (0.448*); 044 (0.452*); P46 (0.484*); 049 (0.485*); K (0.486*); 876 (0.488*); B (0.496*); 2423 (0.500*); D (0.554); G (0.581); F (0.605) |
| Romans (Donker) | A (0.333*); C (0.368*); 01 (0.381*); 01-c (0.381*); 044 (0.381*); L (0.429*); P (0.429*); 049 (0.429*); 223 (0.429*); 33 (0.476*); 876 (0.476*); 1739 (0.476*); 2423 (0.476*); 104 (0.524*); K (0.529*); D (0.571*); G (0.571*); B (0.619) |
| 1 Corinthians (Donker) | A (0.368*); 33 (0.375*); C (0.424*); 01 (0.425*); P46 (0.429*); P (0.474*); 01-c (0.475*); 1739 (0.475*); 044 (0.500*); L (0.525*); B (0.550*); 104 (0.550*); 049 (0.571*); D (0.575*); 223 (0.600); 2423 (0.600); F (0.605); G (0.605); 876 (0.650) |
| 2 Cor. - Titus (Donker) | C (0.220); 104 (0.357*); P (0.362*); 223 (0.366*); 01-c (0.394*); K (0.394*); 33 (0.408*); 876 (0.408*); 1739 (0.408*); 2423 (0.412*); L (0.414*); 01 (0.423*); 044 (0.437*); B (0.446*); A (0.450*); 049 (0.460*); D (0.521*); G (0.571); P46 (0.596); F (0.600) |
| Hebrews (Donker) | P (0.278*); 33 (0.306*); 01-c (0.333*); A (0.333*); 104 (0.333*); 1739 (0.333*); 01 (0.361*); P46 (0.389*); B (0.417*); L (0.417*); 223 (0.452*); 044 (0.472*); 876 (0.472*); 2423 (0.528*); K (0.556*); D (0.583*) |
Table 52. Basil of Caesarea
| Section | Ranked distances |
|---|---|
| Matt (Racine) | E (0.165); Pi (0.174); Omega (0.177); Delta (0.201); 565 (0.214); Sigma (0.225); W (0.240); C (0.256); 700 (0.263); f-13 (0.270); f-1 (0.278); L (0.288); 33 (0.312); Theta (0.338); Aleph (0.366*); B (0.372*); Nyssa (0.407*); D (0.500); it-e (0.563); it-k (0.570); it-a (0.651); it-b (0.663) |
Table 53. Clement of Alexandria
| Section | Ranked distances |
|---|---|
| Matt (Cosaert) | Or (0.283*); UBS4 (0.346); TR (0.347); Omega (0.360); Pi (0.362); E (0.363); B (0.373); Did (0.373*); 1582 (0.388); C (0.389); f-1 (0.390); f-13 (0.392); 892 (0.392); Theta (0.402); Delta (0.422); 33 (0.422); Aleph (0.426); L (0.434); it-a (0.450); it-k (0.457); D (0.462); it-b (0.495) |
| Mark (Cosaert) | E (0.489); TR (0.494); 892 (0.500); f-13 (0.511); it-b (0.513); Omega (0.516); UBS4 (0.529); B (0.534); f-1 (0.545); 1582 (0.545); A (0.557); C (0.557); Pi (0.557); it-k (0.558); 579 (0.568); D (0.581); Psi (0.588); Aleph (0.591); Delta (0.591); it-a (0.592); Theta (0.614) |
| Luke (Cosaert) | Did (0.250*); Or (0.268*); 33 (0.359); Psi (0.376); 1582 (0.380); f-1 (0.384); UBS4 (0.384); 892 (0.388); Omega (0.391); L (0.396); Pi (0.396); it-a (0.399); TR (0.400); Aleph (0.404); B (0.408); P75 (0.412); A (0.414); E (0.416); D (0.418); Theta (0.418); it-b (0.418); f-13 (0.422); Delta (0.433); P45 (0.454); it-e (0.462); 579 (0.463) |
| John (Cosaert) | Or (0.194*); C (0.220*); L (0.224*); Cyr (0.228*); 33 (0.230*); B (0.238*); UBS4 (0.238*); Psi (0.245*); 1582 (0.265*); f-1 (0.272*); Pi (0.276*); E (0.279*); TR (0.286*); Theta (0.293); Delta (0.299); Omega (0.303); Ath (0.306*); W (0.307); P66 (0.308); 892 (0.308*); A (0.309); P75 (0.317); f-13 (0.329); Aleph (0.336); 579 (0.360); D (0.389); it-e (0.402); it-b (0.422); it-a (0.440); Did (0.476) |
Table 54. Cyril of Alexandria
| Section | Ranked distances |
|---|---|
| John (Cunningham) | 33 (0.200); UBS (0.206); C (0.208); L (0.213); B (0.225); 892 (0.239); K (0.247); P75 (0.258); Psi (0.265); 700 (0.276); Maj (0.278); f-1 (0.284); 28 (0.294); 1424 (0.294); Pi (0.297); W (0.298*); 565 (0.298); Delta (0.304); Omega (0.304); 1241 (0.305); A (0.346*); Theta (0.371*); f-13 (0.400*); P66 (0.403*); Aleph (0.413*); D (0.535); it-b (0.575); it-a (0.597); it-e (0.602) |
| John (Fee; ch. 4) | L (0.229); 33 (0.229); C (0.245); 044 (0.250); P66 (0.281*); B (0.281*); Or (0.286*); P75 (0.295*); A (0.302*); 037 (0.312*); 579 (0.312*); W (0.323*); 892 (0.323*); 1241 (0.326*); G (0.333*); 038 (0.344*); E (0.354*); 045 (0.354*); TR (0.354*); 1 (0.375*); 13 (0.375*); D (0.490); Aleph (0.511); it-e (0.611); it-b (0.671) |
| Paul's Letters (Cunningham) | C (0.279); 33 (0.301); Aleph (0.308); A (0.311); UBS (0.318); 81 (0.326); 1739 (0.329); 104 (0.376*); 1175 (0.381*); Psi (0.400*); P (0.404*); Maj (0.415*); 049 (0.419*); L (0.428*); K (0.443*); P46 (0.456*); B (0.475*); D (0.542); G (0.548); F (0.552) |
Table 55. Cyril of Jerusalem
| Section | Ranked distances |
|---|---|
| Mark (Mullen) | 041 (0.367*); 565 (0.367*); A (0.400*); 13 (0.400*); TR (0.400*); 1 (0.414*); E (0.433*); 28 (0.433*); 157 (0.433*); 700 (0.433*); 045 (0.444*); a (0.476*); W (0.500*); 038 (0.500*); b (0.524*); UBS (0.533*); C (0.536*); L (0.552*); Aleph (0.600); B (0.600); D (0.621); k (0.684) |
Table 56. Didymus the Blind
| Section | Ranked distances |
|---|---|
| Matt (Ehrman) | UBS3 (0.319*); 33 (0.337*); L (0.338*); 892 (0.342*); Aleph (0.346*); C (0.350*); B (0.356*); Pi (0.374*); Omega (0.383*); E (0.387*); f-13 (0.387*); TR (0.393*); f-1 (0.399*); Delta (0.405*); Theta (0.447); W (0.453); 1241 (0.463); it-e (0.478*); D (0.530); it-a (0.538); it-b (0.575); it-k (0.579) |
Table 57. Epiphanius of Salamis
| Section | Ranked distances |
|---|---|
| Acts (Osburn) | 1891 (0.290) 81 (0.300) 1739 (0.303) B (0.324) P74 (0.333) 1704 (0.353) 945 (0.382) 1175 (0.382) Aleph (0.412) A (0.412) 630 (0.441) C (0.500) E (0.500) 049 (0.529) 1352 (0.559) P (0.581) TR (0.588) D (0.613) Maj (0.618) H (0.647) L (0.667) 1073 (0.706) |
| Paul's Letters (Osburn) | 104 (0.302) P (0.317) C (0.337) 81 (0.339) 049 (0.368) A (0.378) Aleph (0.388) 33 (0.392) TR (0.403) Maj (0.419) 699 (0.426) 1594 (0.426) B (0.438) L (0.450) P46 (0.454) K (0.454) 1739 (0.457) D (0.543) G (0.589) F (0.597) |
Table 58. Gregory of Nyssa
| Section | Ranked distances |
|---|---|
| Matt (Brooks) | V (0.310*); 1241 (0.330*); E (0.340*); U (0.350*); Omega (0.350*); 1 (0.350*); 33 (0.350*); 544 (0.350*); Sigma (0.360*); Phi (0.360*); 157 (0.360*); C (0.370*); K (0.370*); S (0.370*); Maj (0.370*); 1604 (0.380*); 28 (0.390*); 892 (0.390*); W (0.410); Pi (0.410); UBS (0.410); 565 (0.420); 13 (0.430); 1424 (0.430); L (0.440); 700 (0.440); B (0.450); Aleph (0.470); D (0.490); it-c (0.510); Theta (0.520); it-a (0.540); it-b (0.600) |
| Matt (Racine) | Sigma (0.339); C (0.360*); Delta (0.364*); Omega (0.386*); 33 (0.392*); E (0.393*); L (0.404*); Basil (0.407*); f-1 (0.411*); W (0.421*); Pi (0.439); f-13 (0.439); 565 (0.439); it-e (0.444*); 700 (0.446); Aleph (0.473); B (0.518); Theta (0.518); D (0.562); it-k (0.583); it-a (0.667); it-b (0.739) |
| Luke (Brooks) | 700 (0.260*); C (0.290*); K (0.290*); 33 (0.290*); 544 (0.290*); E (0.300*); 1 (0.300*); S (0.310*); 892 (0.310*); 1241 (0.310*); 1424 (0.310*); Maj (0.310*); V (0.320*); 28 (0.320*); Pi (0.330*); Omega (0.330*); 565 (0.330*); A (0.340*); U (0.340*); Psi (0.340*); UBS (0.340*); 13 (0.350*); P75 (0.360*); 1604 (0.370); Aleph (0.380); L (0.380); 157 (0.400); it-b (0.410); B (0.420); Theta (0.420); it-a (0.420); it-e (0.450); it-c (0.470); W (0.480); D (0.550) |
| John (Brooks; C) | 892 (0.220*); 544 (0.240*); 28 (0.250*); 1604 (0.250*); 1424 (0.260*); V (0.270*); Omega (0.270*); 157 (0.270*); 565 (0.270*); E (0.280*); S (0.280*); Maj. (0.280*); 1241 (0.290*); U (0.300*); Pi (0.300*); 700 (0.300*); K (0.320*); Psi (0.320*); 13 (0.320*); 33 (0.320*); P75 (0.330*); A (0.330*); 1 (0.330*); Theta (0.350*); C (0.360*); L (0.380*); UBS (0.380); P66 (0.390*); it-c (0.410*); Aleph (0.450); B (0.470); it-a (0.470); it-e (0.500); it-b (0.510); W (0.530); D (0.630) |
| Paul's Letters (Brooks) | 075 (0.270*); 0142 (0.270*); P (0.280*); Psi (0.280*); 056 (0.280*); Maj (0.280*); 049 (0.290*); 223 (0.290*); 0150 (0.310*); L (0.320*); 0151 (0.320*); 2423 (0.320*); K (0.330*); C (0.360*); UBS (0.360*); Aleph (0.370*); A (0.370*); 33 (0.370*); 1739 (0.440); B (0.450); P46 (0.490); G (0.570); D (0.600) |
Table 59. Origen
| Section | Ranked distances |
|---|---|
| John (EFH) | UBS3 (0.145); P75 (0.152); C (0.164); B (0.166); L (0.193); Psi (0.231); 33 (0.258); W (0.281); 892 (0.282); P66 (0.293); f-1 (0.293); Pi (0.306*); 579 (0.308*); 565 (0.311*); A (0.312*); Delta (0.324*); 700 (0.326*); E (0.326*); TR (0.331*); Omega (0.333*); 1241 (0.339*); Theta (0.339*); Aleph (0.361*); f-13 (0.364*); it-b (0.495); D (0.524); it-a (0.527); it-e (0.565) |
| John (EFH; P45) | UBS3 (0.145); P75 (0.152); B (0.166); L (0.193); Psi (0.231); 33 (0.258); W (0.281); P66 (0.293); f-1 (0.293); Pi (0.306); 579 (0.308); 565 (0.311); A (0.312*); Delta (0.324*); 700 (0.326*); E (0.326*); TR (0.331*); Omega (0.333*); 1241 (0.339*); Theta (0.339*); Aleph (0.361*); P45 (0.362*); f-13 (0.364*); it-b (0.495); D (0.524); it-a (0.527); it-e (0.565) |
| John (Fee; ch. 4) | B (0.083); C (0.143); P75 (0.155); P66 (0.167); 044 (0.264); Cyr (0.286*); W (0.292*); L (0.306*); 33 (0.306*); A (0.333*); 037 (0.333*); 1 (0.333*); 579 (0.347*); 892 (0.347*); it-e (0.350*); E (0.375*); G (0.375*); 1241 (0.408*); 038 (0.411*); it-b (0.415*); 045 (0.431*); TR (0.431*); 13 (0.458*); Aleph (0.542); D (0.611) |
This discussion focusses on two categories of analysis results given above:
selected data sets
patristic witnesses.
An attempt will be made to cover what seem to be the most important features of the textual landscape revealed by analysis of the more comprehensive data sets. Analysis results for patristic texts will be discussed as well even though the associated data sets tend not to have a broad coverage of witnesses or variation sites.
Discussion typically begins with PAM results for a data set, though CMDS, DC, NJ, and ranked distance results are often covered as well. Patristic data sets are an exception to this general approach. Due to the underlying vagaries of this hard won class of information, the pictures produced by most of the analysis techniques tend to be uninformative. To give an example of the difficulties encountered, PAM analysis often isolates a patristic witness as a singleton as soon as the number of groups is increased beyond a few. Ranked distances provide a viable alternative in these circumstances, allowing some sense of the textual nature of a patristic witness to be gained by identifying its near neighbours. However, the accuracy and precision of the impressions thus obtained may be open to question due to the inherent uncertainties associated with establishing a Church Father's text from quotations.
A few warnings need to be issued before launching into the disquisition. The results are provisional in the sense that any change to the inputs will produce changes in the outputs. If more comprehensive data sets are analysed then their results will vary from those presented here. The important question is, how much will they vary? If the data set analysed here is already quite comprehensive and is not marred by some form of systematic bias then the corresponding results can be expected to be consistent with any obtained from more comprehensive data sets.[23]
Each analysis method presents its own view of the textual landscape occupied by New Testament witnesses. While these views are generally consistent, there are cases where the analysis modes differ with respect to the alignments of particular witnesses. If this happens then due caution should be exercised when drawing conclusions about the textual complexions of those witnesses. For analysis methods which divide texts into branches or groups (i.e. DC, NJ, and PAM), any text which shares characteristics of multiple branches or groups (sometimes called a "mixed" text) is prone to jump from one place to another if even slight changes are made to the data upon which the analysis is based. The respective analysis techniques will often agree on the core members of a group or branch but disagree on the placement of peripheral ones.
All this raises the question of how best to describe a witness when the different analysis modes present conflicting views of its affiliations. The ranked distance result acts as an arbiter in such cases, providing a standard against which to assess aspects of textual relationships indicated by the respective modes of analysis.[24]
...
In deference to Streeter, I begin discussion of the group structure of available New Testament witnesses with the Gospel of Mark:
Mark provided very few lessons for the selection read in the public services of the Church. It was much less used and much less commented on than the other Gospels... Hence the comparative carelessness shown in correcting Mark to the fashionable type of text is easily accounted for. There emerges a principle of some importance... Seeing that the Gospel of Mark has escaped Byzantine revision in more copies and to a greater extent than the other Gospels, it follows that our materials for reconstructing the old local texts are far more abundant and trustworthy in this Gospel. From this we deduce the following canon of textual criticism. Research into the pedigree of a MS. should begin with a study of its text of Mark.[25]
...
Table 60. Church Fathers, dates, and locations
| Name | Dates | Locations |
|---|---|---|
| Athanasius | c. 297 - 373 | Alexandria, Egypt |
| Basil of Caesarea | c. 330 - 379 | Caesarea, Cappadocia |
| Clement of Alexandria | c. 150 - c. 215 | Rome, Italy; Ephesus, Asia; Alexandria, Egypt |
| Cyril of Alexandria | c. 376 – 444 | Alexandria, Egypt |
| Cyril of Jerusalem | c. 315 - 386 | Jerusalem, Judea |
| Didymus the Blind | c. 313 – 398 | Alexandria, Egypt |
| Epiphanius of Salamis | c. 315 – 403 | Salamis, Cyprus |
| Gregory of Nyssa | c. 335 – c. 395 | Nyssa, Cappadocia |
| Origen | 185 - 254 | Alexandria, Egypt (until 231); Caesarea, Judea (from 231) |
Look at Gregory Thaumaturgus (~ 270), Methodius of Olympus (d. 311)

Groups exist but are not always well defined.
NJ branches have points of contact with PAM divisions but the correspondence is sometimes weak.
PAM divisions have points of contact with traditional divisions. E.g. in the six-way partition: [cop] = Alexandrian; [K] = Byzantine; [arm] = Streeter's Eastern; [it-d] + [it-b] = Western; [it-aur] = Vulgate.
Some branches are associated with ancient versions.
If the sampled texts developed from a single initial text then it is reasonable to look for the initial text's nearest extant relatives where major branches of the NJ tree converge. Accordingly, key texts to consider when recovering the initial text of Matthew include 33, 892, and 1546.
One way to recover the initial text at every variation site is to take the most frequent reading across a number of texts located near the junction of major branches of the NJ tree. Another approach is to take the most frequent reading across group medoids. Branches or groups that are known to be secondary (e.g. [it-aur] (6), namely the Vulgate group) can be eliminated from consideration before using these recovery procedures.
Table 61. UBS2 Luke PAM
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 |
|
Cyril it-e Marcion syr-s Origen it-aur Augustine eth syr-pal Tertullian Eusebius | ||||||||||||
| 7 |
|
arm Cyril Origen it-c eth syr-pal | ||||||||||||
| 21 |
|
33 1241 syr-pal eth Marcion Irenaeus Ambrose Tertullian Cyril Origen | Eusebius 1546 Psi Pi Xi 1009 |
Key texts to consider when recovering initial text based on NJ result: 700, 892, Theta, Family 13, Peshitta Syriac, Diatessaron.
NJ result indicates that Syriac (except Harclean and Palestinian), Armenian, Georgian, and Latin occupy the same branch which is devoid of Greek MS support (except D).
21-way partition has a cluster (W, Psi, Family 1, 565, 1009, 1079, 1365, 1546) centred on Basil (Cappadocia, d. 379). Did the writings of Church Fathers interfere with the biblical text? Monks might be expected to use theologically-correct phrases when copying (cf. Ehrman). Some members of this cluster are in Streeter's Caesarean group in Mark.
D, it-d, and Eusebius associate in 21-way partition. This suggests a link between the D-text and the text used by Eusebius. Is this a clue to the provenance of Codex Bezae? (Spelling analysis would be interesting.)

Table 62. UBS2 John PAM
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 |
|
arm syr-c Tertullian geo Cyril vg X Eusebius cop Aleph-c | ||||||||||||||
| 5 |
|
arm syr-c Cyprian syr-s it-f vg geo Diatessaron 33 syr-p Tertullian eth Cyril it-q X syr-pal Eusebius Chrysostom 1230 cop goth Aleph-c 1253 Pi 1646 2174 Theodoret | ||||||||||||||
| 19 |
|
syr-c syr-pal eth Diatessaron Cyril Eusebius | 1010 Lect 1071 syr-p 700 W-supp 1365 1230 X goth f-13 1344 Tertullian Origen K Chrysostom Byz it-r-1 it-l 1079 1253 28 Nonnus Aleph-c it-ff-2 2174 |
...
...
...
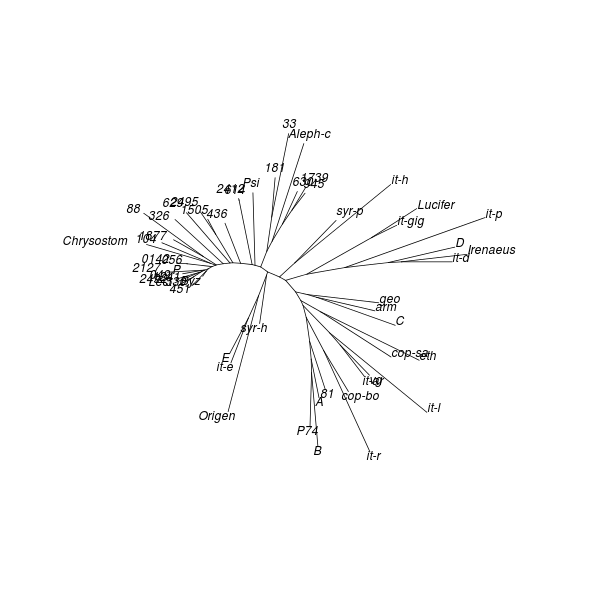
Table 63. UBS2 Acts PAM
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 |
|
eth 1739 Lucifer 181 Origen Aleph-c | |||||||||||
| 11 |
|
it-p | 33 syr-h Origen it-r cop-bo arm Psi | ||||||||||
| 17 |
|
it-h it-l it-p it-r syr-p cop-sa geo eth | cop-bo 33 C |
...
...
...
Table 64. PAM (Mark, UBS4)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 |
|
C syr-s arm vg | ||||||||||
| 6 |
|
Theta f-13 geo eth 565 892 | ||||||||||
| 11 |
|
W it-k | eth 892 L |
The major NJ tree branches correspond to traditional groups: Alexandrian (B, C, L, Delta, Psi, cop-bo, cop-sa, ...); Byzantine (A, E, F, G, H, N, ...); Streeter's Eastern (W, Theta, Family 1, Family 13, 28, 565, 700, syr-s, arm, geo); Western (D, Old Latins, Vulgate and Vulgate-like).
Three of the branches are associated with ancient versions: Alexandrian and Coptic; Eastern and Old Syriac; Western and Old Latin.
Key texts to consider when recovering the initial text of Mark (i.e. those near the convergence of major branches): 33, syr-h, eth, 579, syr-p, syr-pal, 700, Family 13.
The CMDS map shows that Jerome's Vulgate (vg) stands between a group of Old Latin texts (a, b, c, d, ff2, i, r1) and the Byzantine cluster. This indicates that the Greek texts Jerome used to revise the Latin of Mark's Gospel were of the Byzantine variety. Jerome said that the Greek copies he used were “old indeed.” Unless Jerome was badly mistaken about the age of these Greek copies, it seems that the Byzantine variety existed well before his time.
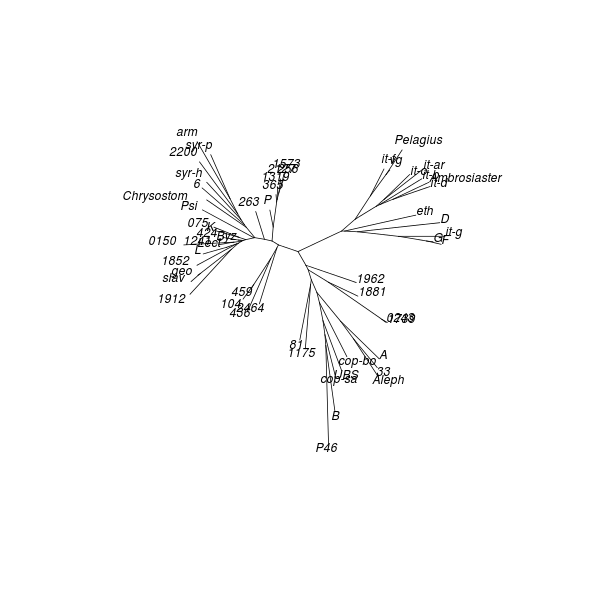

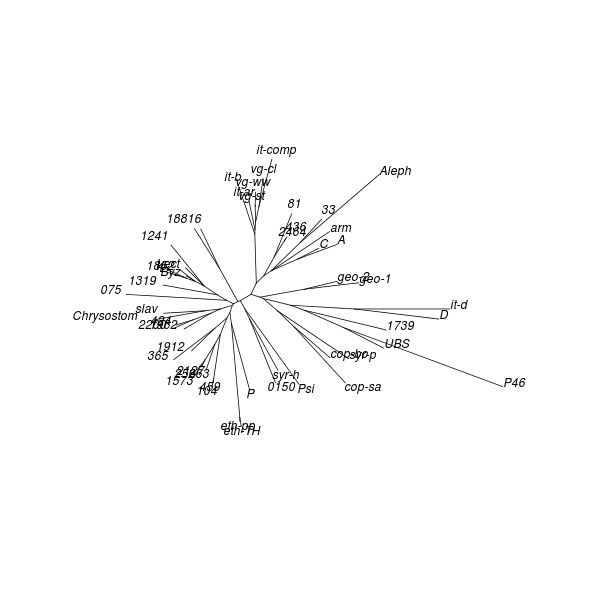
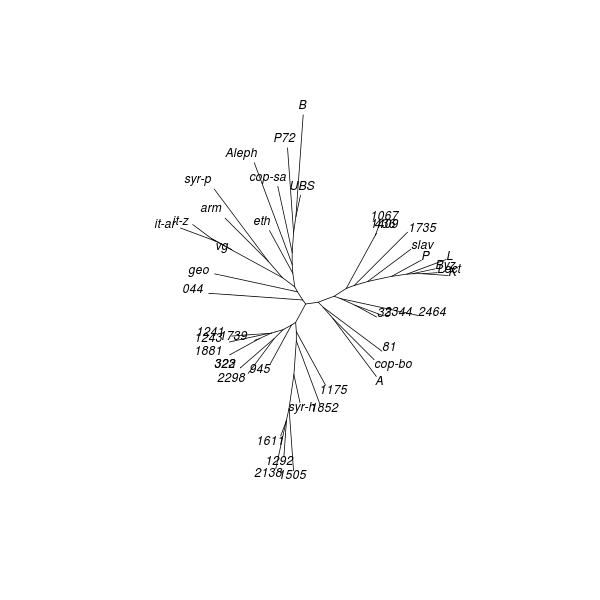
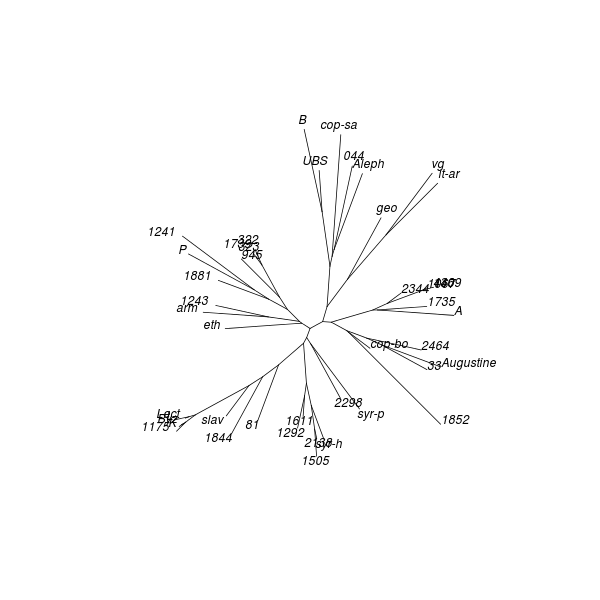
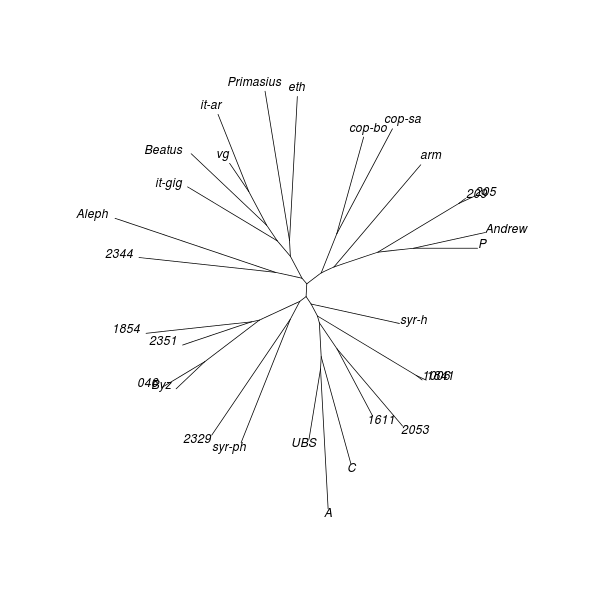
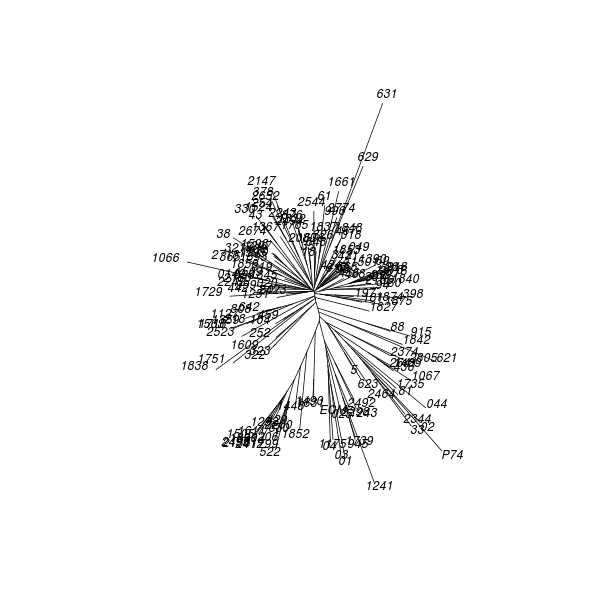
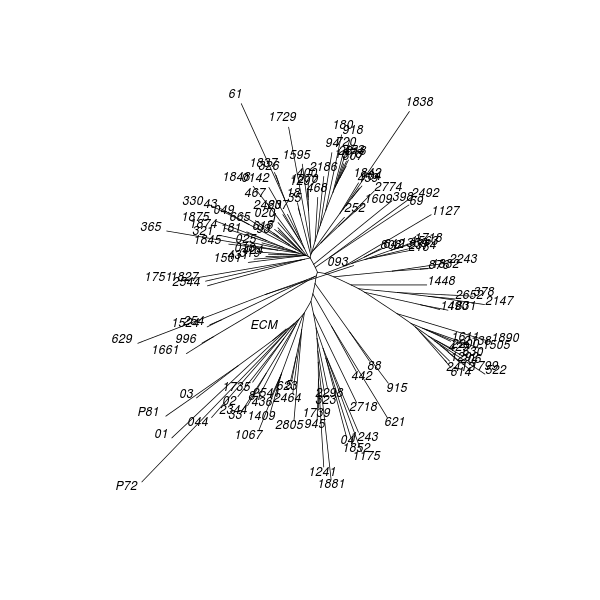

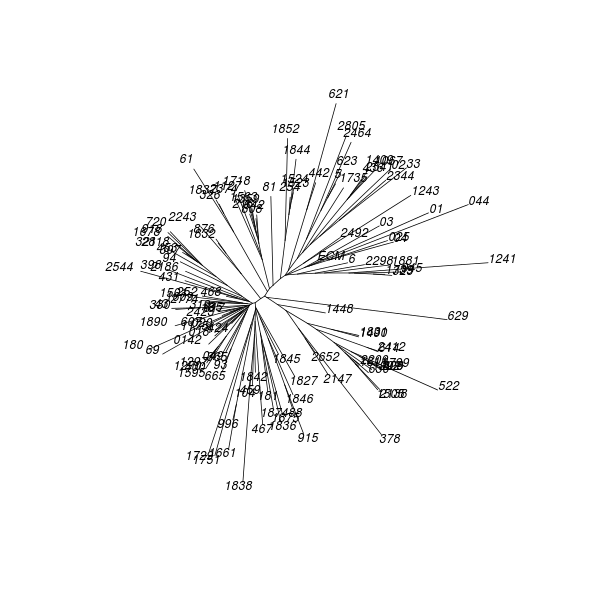
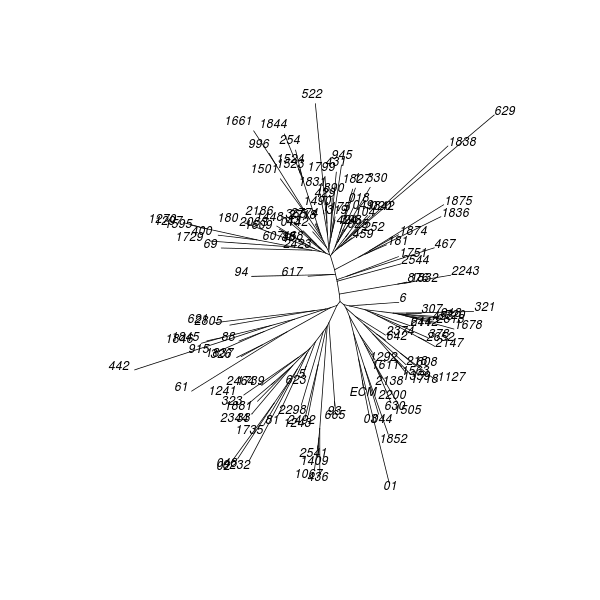


PAM partitions of INTF Parallel Pericopes data set can be compared with classifications proposed by (1) von Soden and (2) Wisse.
Table 65. PAM (Luke, INTF-Parallel)
| No. | Groups and their [medoids] | Singletons | Poorly classified (worst last) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 |
|
33 04 892 | |||||||||||||||
| 11 |
|
05 | 044 1337 1241 1692 807 1342 1253 233 2680 954 892 851 61 979 713 1336 1093 1661 191 1329 1009 1339 1338 28 18 1334 1328 35 372 2737 31 157 1502 427 565 1333 33 1330 1602 1823 2766 150 174 021 792 1071 222 79 033 700 1345 04 032 040 038 | ||||||||||||||
| 41 |
|
01 033 038 04 05 1009 1071 1093 1241 1253 1330 1337 1342 157 1661 1692 176 222 2542 2680 579 700 740 79 792 863 892 | 044 28 150 1502 427 565 1823 1602 31 2766 021 791 1333 1506 174 1345 191 954 |
[826] (i.e. Family 13) is highly coherent, hardly changing as the data set is partitioned into more groups. A two-way partition of this data set separates Family 13 from the rest.
Streeter classifies some members of [024] (11) (i.e. 032, 038, 157, 700, 1071) as Caesarean and others as Alexandrian (i.e. 04, 033, 040, 33, 892). Wisse classifies a number of [024] (11) members into his B group for one or more of his test passages (i.e. 032, 040, 33, 157, 700, 892).
Table 66. Comparison of groups (11-way PAM, von Soden, and Wisse)
| PAM | von Soden | Wisse | Other labels |
|---|---|---|---|
| [A] | H (5/5) | B (5/5) | Alexandrian |
| [3] | I (14/37), Kx (11/37), K1 (4/37), Ki (4/37), Kr (2/37) | Kx (20/38), Kmix (4/38), Mix (4/38), 22 (3/38), Λ (2/38), Cl 1675 (2/38) | Byzantine |
| [041] | Iκa (4/4) | Πa (5/5) | Family Π |
| [35] | I (14/29), Kx (8/29), Kr (6/29) | Mix (10/33), Kx (9/33), Kr (6/33), Kmix (3/33), M (2/33) | Byzantine |
| [024] | I (6/13), H (4/13), A (2/13) | Mix (7/9), B (2/9) | |
| [1582] | Iη (6/6) | 1 (7/7) | Family 1 |
| [1012] | I (2/3) | Cl 1012 (3/3) | |
| [826] | Iι (9/9) | 13 (9/9) | Family 13 |
| [184] | Iβ (4/7), Iφ (2/7) | 1216 (8/10), 16 (2/10) | |
| [1446] | Iκ (3/4) | Cl 827 (4/4) |
Note
The comparison is based on Wisse's table of profile classifications.[26] Each PAM group is labelled by its medoid (e.g. [A], which stands for the Ausgangstext, not Codex Alexandrinus). Figures in parentheses (e.g. 3/4) give the proportion of witnesses in a PAM group that von Soden or Wisse place together in one of their groups. E.g. in the [1446] row, of four witnesses in the PAM group whose classifications by von Soden are given, three are in his Iκ group. In the von Soden column, I and A categories count all witnesses in the corresponding subgroups. In some cases, however, subgroups are specifically listed. For figures given in the Wisse column, each witness is assigned the majority classification across Wisse's three test passages (i.e. Luke chapters 1, 10, and 20). A witness is not counted if there is no majority classification. For von Soden and Wisse columns, entries are made only for those categories which include more than one witness from the corresponding PAM group.
In an 11-way partition, PAM groups [A], [041], [1582], [1012], [826], and [1446] correlate well with groups identified by von Soden and Wisse while PAM groups [3], [35], [024], and [184] do not. Group [184] would be a good match if compared with combinations of (1) von Soden's Iβ and Iφ and (2) Wisse's groups 16 and 1216.
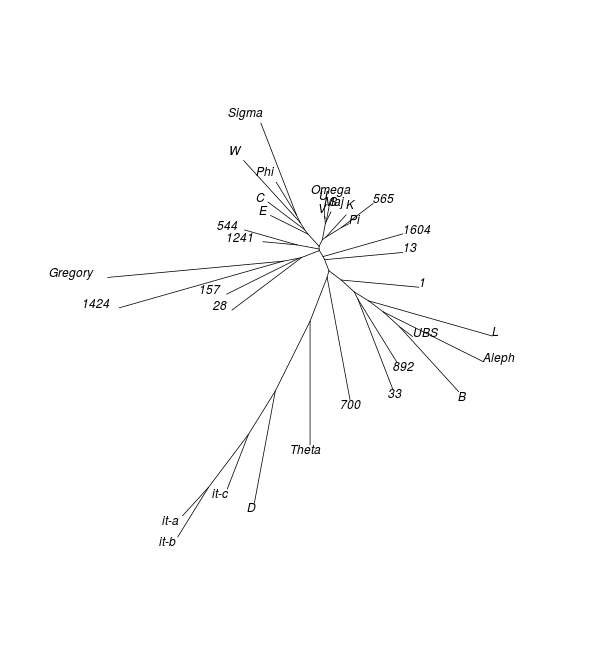
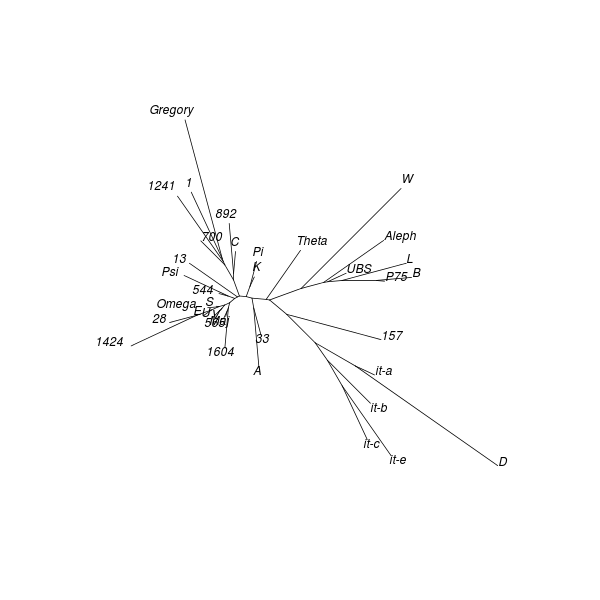
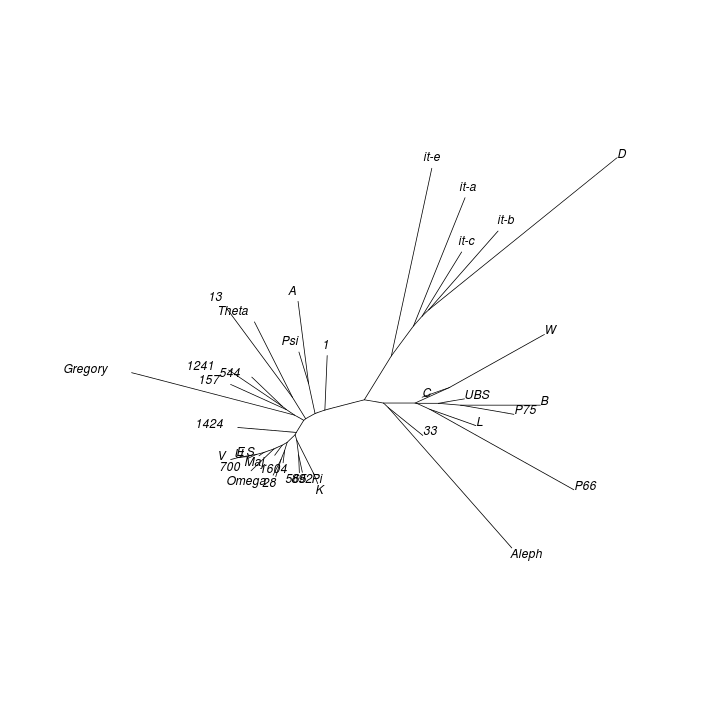
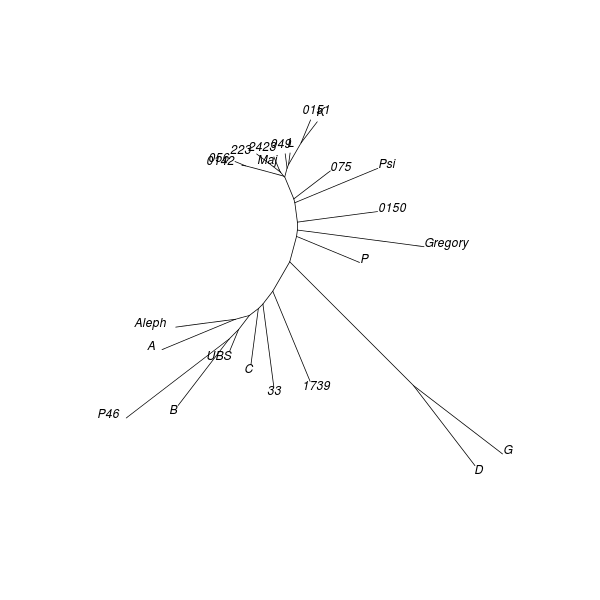
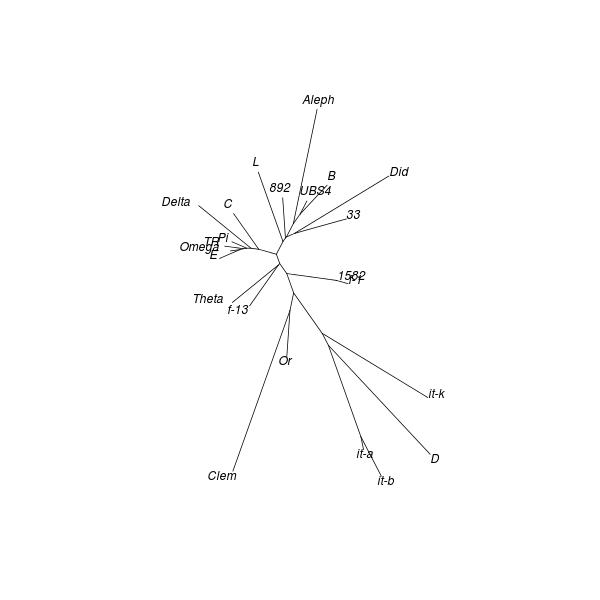


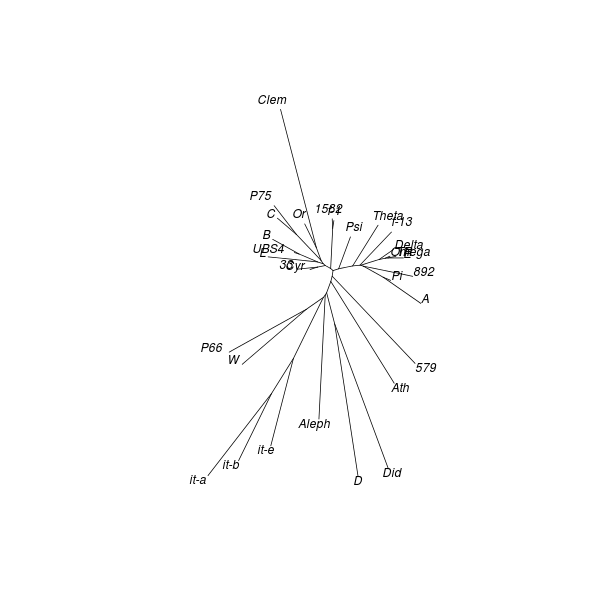
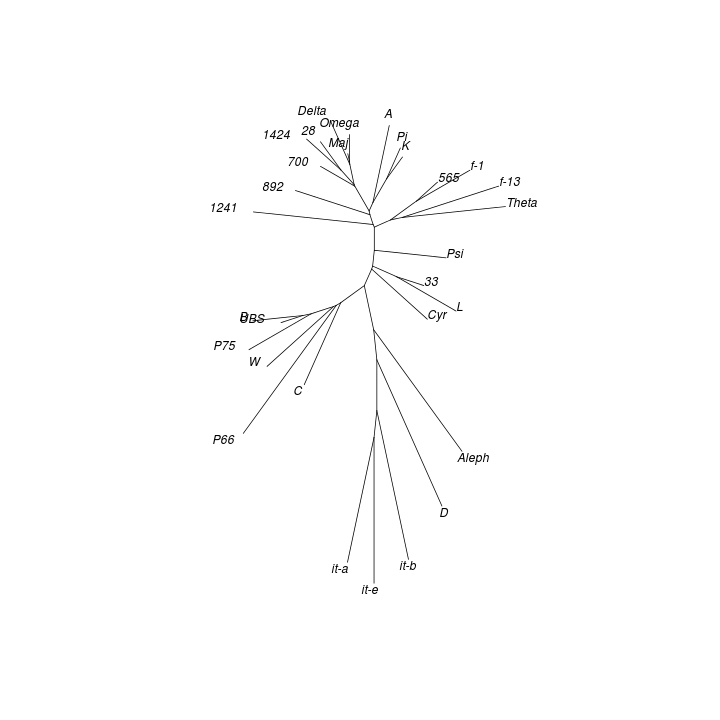
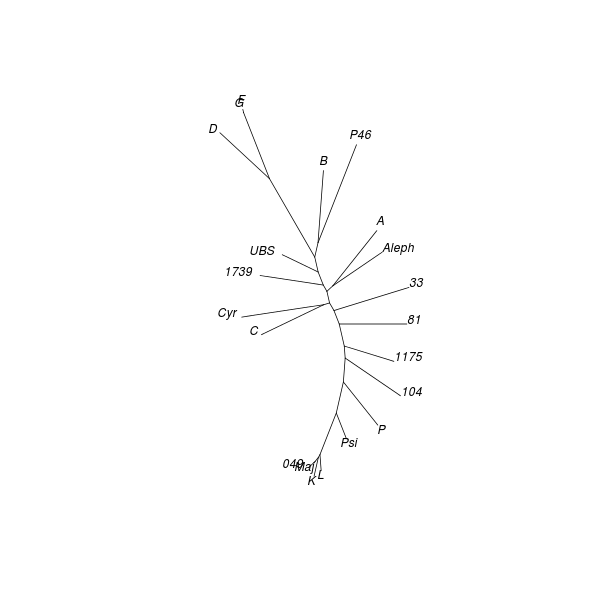

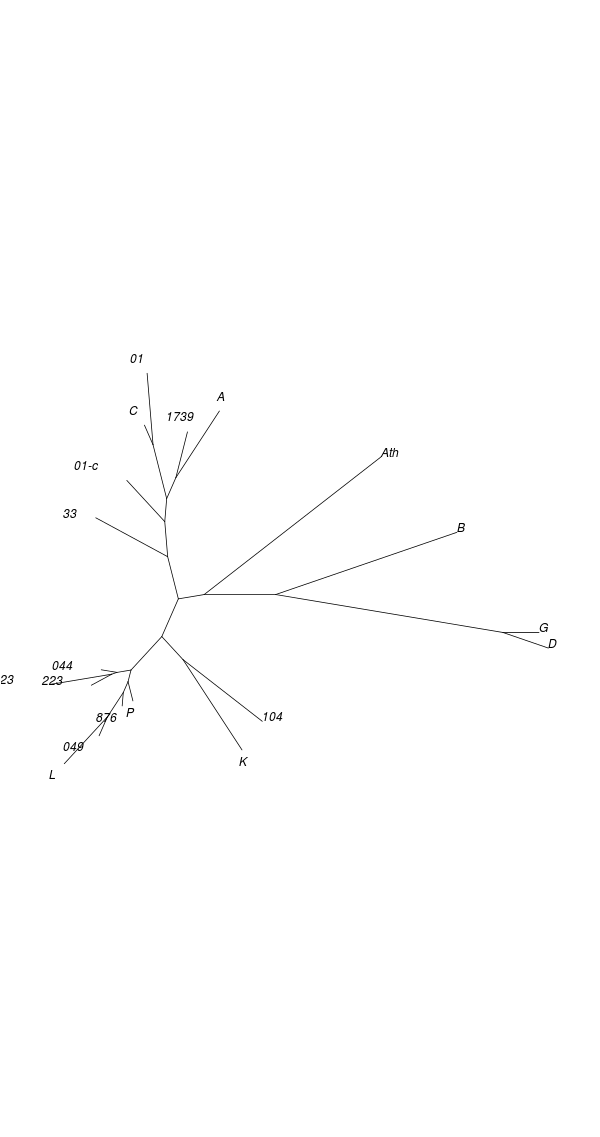
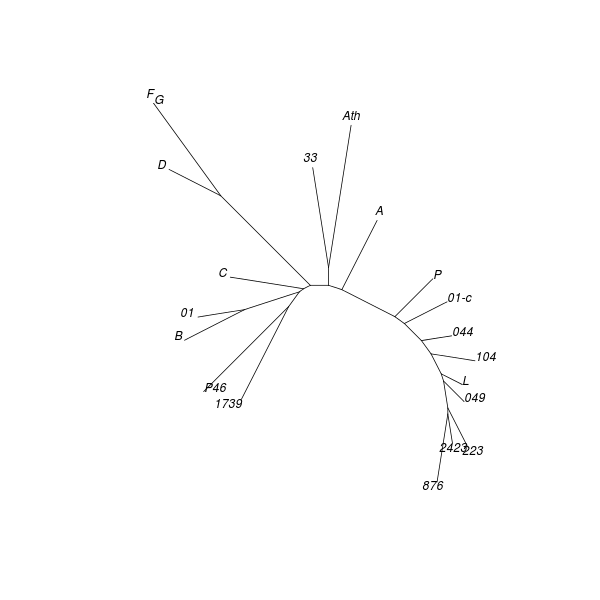
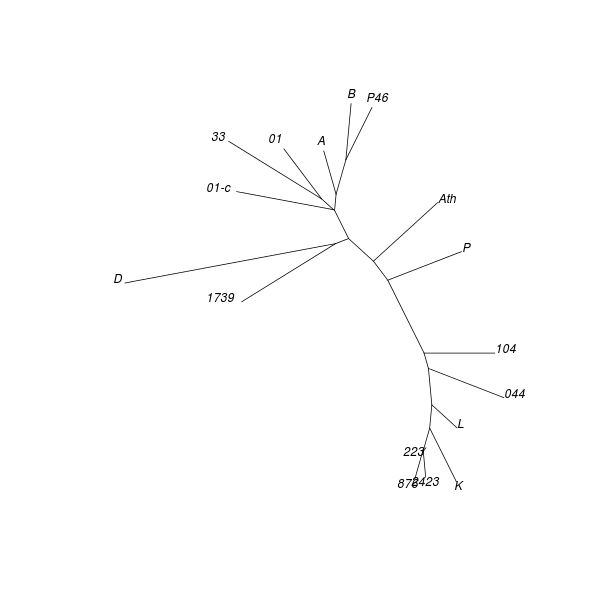
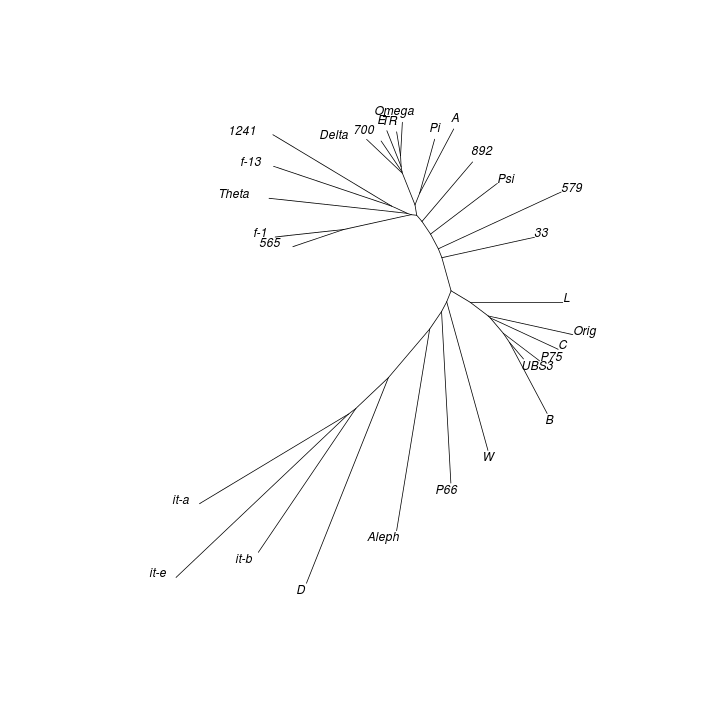
The analysis results presented above highlight variations between witnesses of the New Testament. This naturally raises the question of what difference the variations make to the meaning of the text. Most variations are of little consequence — whether an added or dropped article, change of word order, or substitution of a synonymous phrase. Other variations have larger semantic effect, the two most extreme examples being Mark 16.9-20 and John 7.53-8.11 that are absent from a number of witnesses.
One way to convey how much difference the variations make is to provide translations of a number of textual varieties for the same section of text. The following parallel translation of four varieties of the first chapter of Mark highlights the variation sites given in the United Bible Societies Greek New Testament. This edition only presents a selection of textual variations:
The intention was to provide an apparatus where the most important international translations of the New Testament show notes referring to textual variants or even have differences in their translations or interpretations. Other groups of variants have also been included when for various reasons they are significant and worthy of consideration.[27]
The variation sites presented in the UBS apparatus constitute a small proportion of the total number that exist. Nevertheless, those presented are the most important from a semantic point of view, and the great majority of variations not presented in the UBS apparatus have negligible semantic effect. Consequently, looking at these variation sites should give a reliable impression of the magnitude of difference in meaning between textual varieties.
The textual varieties shown in the parallel translation consist of four clusters identified by reference to the DC dendrogram of the UBS4 data set for Mark:[28]
A: The mainly Byzantine cluster comprised of A ... syr-pal
B: Aleph B C L Delta Psi 892 1342 cop-bo cop-sa it-k
C: W Theta f-1 28 205 565 arm geo syr-s
D: D it-a it-b it-c it-d it-ff-2 it-i it-q it-r-1
For each variation unit, the reading supported by a textual variety is taken to be the one that occurs most frequently among its members. To illustrate, suppose that a variation unit has three readings and that two witnesses in cluster C have the first, three have the second, and four have the third. The reading supported by cluster C would then be taken to be the third. For the purpose of this exercise, if a tie occurs then the supported reading is taken to be the one with the greatest tendency to isolate the variety.
The highlighted passages show how much the more important differences encountered in the first chapter of Mark's Gospel affect the meaning of the text. Most of the differences are hardly worth a second thought, though a few do convey a different shade of meaning. If this one chapter is representative (and there is no reason to think it is not) then it is fair to say that most of the textual variation in the New Testament has little semantic effect. That said, there are a few places (such as Mark 16.9-20 and John 7.53-8.11) where the differences are significant.
Table 67. Four-way parallel translation of Mark chapter one
| Reference | A | B | C | D |
|---|---|---|---|---|
| 1.1 | The beginning of the good news about Jesus Christ, Son of God. | The beginning of the good news about Jesus Christ, Son of God. | The beginning of the good news about Jesus Christ. | The beginning of the good news about Jesus Christ, Son of God. |
| 1.2 | As written in the prophets, "Look, I send my messenger before you, who will prepare your way;" | As written in the prophet Isaiah, "Look, I send my messenger before you, who will prepare your way;" | As written by Isaiah the prophet, "Look, I send my messenger before you, who will prepare your way;" | As written in the prophet Isaiah, "Look, I send my messenger before you, who will prepare your way;" |
| 1.3 | "A voice shouting in the wilderness, 'Prepare the way of the Lord! Make his paths straight!'" | "A voice shouting in the wilderness, 'Prepare the way of the Lord! Make his paths straight!'" | "A voice shouting in the wilderness, 'Prepare the way of the Lord! Make his paths straight!'" | "A voice shouting in the wilderness, 'Prepare the way of the Lord! Make his paths straight!'" |
| 1.4 | John appeared, baptizing in the wilderness and announcing a baptism of a changed attitude for forgiveness of wrong deeds. | John the Baptist appeared in the wilderness, and [was] announcing a baptism of a changed attitude for forgiveness of wrong deeds. | John the Baptist appeared in the wilderness, and [was] announcing a baptism of a changed attitude for forgiveness of wrong deeds. | John appeared in the wilderness, baptizing and announcing a baptism of a changed attitude for forgiveness of wrong deeds. |
| 1.5 | They went out to him, all of the land of Judea and those of Jerusalem, and were baptized by him, confessing their wrong deeds. | They went out to him, all of the land of Judea and those of Jerusalem, and were baptized by him, confessing their wrong deeds. | They went out to him, all of the land of Judea and those of Jerusalem, and were baptized by him, confessing their wrong deeds. | They went out to him, all of the land of Judea and those of Jerusalem, and were baptized by him, confessing their wrong deeds. |
| 1.6 | John was clothed [with] camel hair and a leather covering around his waist; he ate locusts and wild honey. | John was clothed [with] camel hair and a leather covering around his waist; he ate locusts and wild honey. | John was clothed [with] camel hair and a leather covering around his waist; he ate locusts and wild honey. | John was clothed [with] camel hair and a leather covering around his waist; he ate locusts and wild honey. |
| 1.7 | He gave notice saying, "One more powerful than me comes after me, whose sandal straps I am not worthy to bend down and untie." | He gave notice saying, "One more powerful than me comes after me, whose sandal straps I am not worthy to bend down and untie." | He gave notice saying, "One more powerful than me comes after me, whose sandal straps I am not worthy to bend down and untie." | He gave notice saying, "I baptize you in water. One more powerful than me comes after me, whose sandal straps I am not worthy to bend down and untie." |
| 1.8 | "I baptize you in water; he will baptize you in the Holy Spirit." | "I baptize you [in] water; he will baptize you in the Holy Spirit." | "I baptize you in water; he will baptize you in the Holy Spirit." | "He will baptize you in the Holy Spirit." |
| 1.9 | In those days Jesus came from Nazareth, Galilee, and was baptized in the Jordan by John. | In those days Jesus came from Nazareth, Galilee, and was baptized in the Jordan by John. | In those days Jesus came from Nazareth, Galilee, and was baptized in the Jordan by John. | In those days Jesus came from Nazareth, Galilee, and was baptized in the Jordan by John. |
| 1.10 | Then coming up from the water he saw the heavens being torn open and the Spirit coming down to him like a dove. | Then coming up from the water he saw the heavens being torn open and the Spirit coming down to him like a dove. | Then coming up from the water he saw the heavens being torn open and the Spirit coming down to him like a dove; | Then coming up from the water he saw the heavens being torn open and the Spirit coming down to him like a dove; |
| 1.11 | There came from the heavens a voice: "You are my beloved Son; I am delighted with you." | There came from the heavens a voice: "You are my beloved Son; I am delighted with you." | from the heavens he heard a voice: "You are my beloved Son; I am delighted with you." | from the heavens a voice: "You are my beloved Son; I am delighted with you." |
| 1.12 | Then the Spirit drives him into the wilderness. | Then the Spirit drives him into the wilderness. | Then the Spirit drives him into the wilderness. | Then the Spirit drives him into the wilderness. |
| 1.13 | He was in the desert forty days being tested by Satan; he was with the wild animals and the angels waited on him. | He was in the desert forty days being tested by Satan; he was with the wild animals and the angels waited on him. | He was in the desert forty days being tested by Satan; he was with the wild animals and the angels waited on him. | He was in the desert forty days being tested by Satan; he was with the wild animals and the angels waited on him. |
| 1.14 | After John had been arrested, Jesus went into Galilee announcing the good news of the kingdom of God | After John had been arrested, Jesus went into Galilee announcing the good news of God | After John had been arrested, Jesus went into Galilee announcing the good news of God | After John had been arrested, Jesus went into Galilee announcing the good news of the kingdom of God |
| 1.15 | saying, "The time has come and God's kingdom is near. Change your attitude and believe the good news." | saying, "The time has come and God's kingdom is near. Change your attitude and believe the good news." | saying, "The time has come and God's kingdom is near. Change your attitude and believe the good news." | saying, "The time has come and God's kingdom is near. Change your attitude and believe the good news." |
| 1.16 | Passing by the Sea of Galilee he saw Simon and Andrew, Simon's brother, throwing a net into the sea. (They were fishermen.) | Passing by the Sea of Galilee he saw Simon and Andrew, Simon's brother, throwing a net into the sea. (They were fishermen.) | Passing by the Sea of Galilee he saw Simon and Andrew, Simon's brother, throwing a net into the sea. (They were fishermen.) | Passing by the Sea of Galilee he saw Simon and Andrew, Simon's brother, throwing nets into the sea. (They were fishermen.) |
| 1.17 | Jesus said to them, "Come with me and I will make you into fishers of men." | Jesus said to them, "Come with me and I will make you into fishers of men." | Jesus said to them, "Come with me and I will make you into fishers of men." | Jesus said to them, "Come with me and I will make you into fishers of men." |
| 1.18 | Then they left the nets and followed him. | Then they left the nets and followed him. | Then they left the nets and followed him. | Then they left the nets and followed him. |
| 1.19 | Going a bit further he saw Jacob Zebedee and his brother John who were in the boat fixing the nets. | Going a bit further he saw Jacob Zebedee and his brother John who were in the boat fixing the nets. | Going a bit further he saw Jacob Zebedee and his brother John who were in the boat fixing the nets. | Going a bit further he saw Jacob Zebedee and his brother John who were in the boat fixing the nets. |
| 1.20 | Then he called them. Leaving their father Zebedee in the boat with the hired hands, they went after him. | Then he called them. Leaving their father Zebedee in the boat with the hired hands, they went after him. | Then he called them. Leaving their father Zebedee in the boat with the hired hands, they went after him. | Then he called them. Leaving their father Zebedee in the boat with the hired hands, they went after him. |
| 1.21 | They go into Capernaum. Then, on the Sabbath, having gone into the synagogue, he taught. | They go into Capernaum. Then, on the Sabbath, having gone into the synagogue, he taught. | They go into Capernaum. Then, on the Sabbath, having gone into the synagogue, he taught. | They go into Capernaum. Then, on the Sabbath, having gone into the synagogue, he taught. |
| 1.22 | They were shocked by his teaching because he taught them like someone with authority, not like the scholars. | They were shocked by his teaching because he taught them like someone with authority, not like the scholars. | They were shocked by his teaching because he taught them like someone with authority, not like the scholars. | They were shocked by his teaching because he taught them like someone with authority, not like the scholars. |
| 1.23 | Then there was a man with an unclean spirit in their synagogue. He screamed, | Then there was a man with an unclean spirit in their synagogue. He screamed, | Then there was a man with an unclean spirit in their synagogue. He screamed, | Then there was a man with an unclean spirit in their synagogue. He screamed, |
| 1.24 | "What's with us and you, Jesus Nazarene? Have you come to destroy us? I know who you are — God's holy one!" | "What's with us and you, Jesus Nazarene? Have you come to destroy us? I know who you are — God's holy one!" | "What's with us and you, Jesus Nazarene? Have you come to destroy us? I know who you are — God's holy one!" | "What's with us and you, Jesus Nazarene? Have you come to destroy us? I know who you are — God's holy one!" |
| 1.25 | Jesus told it off saying, "Be quiet! Get out of him!" | Jesus told it off saying, "Be quiet! Get out of him!" | Jesus told it off saying, "Be quiet! Get out of him!" | Jesus told it off saying, "Be quiet! Get out of him!" |
| 1.26 | Throwing a fit and shouting with a loud voice, the unclean spirit got out of him. | Throwing a fit and shouting with a loud voice, the unclean spirit got out of him. | Throwing a fit and shouting with a loud voice, the unclean spirit got out of him. | Throwing a fit and shouting with a loud voice, the unclean spirit got out of him. |
| 1.27 | All being shocked they asked each other, "What is this? What new teaching is this, that with authority he gives orders even to unclean spirits and they obey him?" | All being shocked they asked each other, "What is this new teaching with authority? He gives orders even to unclean spirits and they obey him." | All being shocked they asked each other, "What is this, this new teaching with authority? He gives orders even to unclean spirits and they obey him." | All being shocked they asked each other, "What is that teaching, this new one with authority, that he gives orders even to unclean spirits and they obey him?" |
| 1.28 | The news about him then got out everywhere in the whole region of Galilee. | The news about him then got out everywhere in the whole region of Galilee. | The news about him then got out everywhere in the whole region of Galilee. | The news about him then got out everywhere in the whole region of Galilee. |
| 1.29 | Then, leaving the synagogue, they went to Simon and Andrew's house with Jacob and John. | Then, leaving the synagogue, they went to Simon and Andrew's house with Jacob and John. | Then, leaving the synagogue, he went to Simon and Andrew's house with Jacob and John. | Leaving the synagogue, he went to Simon and Andrew's house with Jacob and John. |
| 1.30 | Simon's mother-in-law lay sick with fever. Then they tell him about her. | Simon's mother-in-law lay sick with fever. Then they tell him about her. | Simon's mother-in-law lay sick with fever. Then they tell him about her. | Simon's mother-in-law lay sick with fever. Then they tell him about her. |
| 1.31 | He went over, took hold of her hand, and helped her up. The fever left her and she began to wait on them. | He went over, took hold of her hand, and helped her up. The fever left her and she began to wait on them. | He went over, took hold of her hand, and helped her up. The fever left her and she began to wait on them. | He went over, took hold of her hand, and helped her up. The fever left her and she began to wait on them. |
| 1.32 | In the evening after sunset they began to bring everyone who was suffering from sickness and the demonized. | In the evening after sunset they began to bring everyone who was suffering from sickness and the demonized. | In the evening after sunset they began to bring everyone who was suffering from sickness and the demonized. | In the evening after sunset they began to bring everyone who was suffering from sickness and the demonized. |
| 1.33 | The whole town was gathered at the door. | The whole town was gathered at the door. | The whole town was gathered at the door. | The whole town was gathered at the door. |
| 1.34 | He cured a lot who suffered a variety of sicknesses and got out a lot of demons. He did not allow the demons to speak because they had recognized him. | He cured a lot who suffered a variety of sicknesses and got out a lot of demons. He did not allow the demons to speak because they had recognized him to be Christ. | He cured a lot who suffered a variety of sicknesses and got out a lot of demons. He did not allow the demons to speak because they had recognized him to be Christ. | He cured a lot who suffered a variety of sicknesses and got out a lot of demons. He did not allow the demons to speak because they had recognized him. |
| 1.35 | Getting up early while it was still dark, he left and went away to a deserted spot and prayed there. | Getting up early while it was still dark, he left and went away to a deserted spot and prayed there. | Getting up early while it was still dark, he left and went away to a deserted spot and prayed there. | Getting up early while it was still dark, he left and went away to a deserted spot and prayed there. |
| 1.36 | Simon and those with him hunted him down. | Simon and those with him hunted him down. | Simon and those with him hunted him down. | Simon and those with him hunted him down. |
| 1.37 | They find him and say to him, "Everyone is looking for you." | They find him and say to him, "Everyone is looking for you." | They find him and say to him, "Everyone is looking for you." | They find him and say to him, "Everyone is looking for you." |
| 1.38 | He says to them, "Let's go somewhere else -- into the next towns -- so that I can campaign there too, because I came out for this." | He says to them, "Let's go somewhere else -- into the next towns -- so that I can campaign there too, because I came out for this." | He says to them, "Let's go somewhere else -- into the next towns -- so that I can campaign there too, because I came out for this." | He says to them, "Let's go somewhere else -- into the next towns -- so that I can campaign there too, because I came out for this." |
| 1.39 | He was campaigning in their synagogues throughout Galilee, driving out demons too. | He went campaigning in their synagogues throughout Galilee, driving out demons too. | He was campaigning in their synagogues throughout Galilee, driving out demons too. | He was campaigning in their synagogues throughout Galilee, driving out demons too. |
| 1.40 | A leper came towards him begging and kneeling to him, saying "If you want to you can make me clean." | A leper came towards him begging and kneeling, saying "If you want to you can make me clean." | A leper came towards him begging and kneeling, saying "If you want to you can make me clean." | A leper came towards him begging, saying "If you want to you can make me clean." |
| 1.41 | Deeply moved, reaching out his hand he takes hold of him and says: "I want to. Be clean." | Deeply moved, reaching out his hand he takes hold of him and says: "I want to. Be clean." | Deeply moved, reaching out his hand he takes hold of him and says: "I want to. Be clean." | Getting annoyed, reaching out his hand he takes hold of him and says: "I want to. Be clean." |
| 1.42 | Then the leprosy left him and he was cleansed. | Then the leprosy left him and he was cleansed. | Then the leprosy left him and he was cleansed. | Then the leprosy left him and he was cleansed. |
| 1.43 | He told him off then sent him away. | He told him off then sent him away. | He told him off then sent him away. | He told him off then sent him away. |
| 1.44 | He says to him, "Look, don't say anything to anyone. Instead, go off, show yourself to the priest, and offer what Moses commanded for your cleansing as proof to them." | He says to him, "Look, don't say anything to anyone. Instead, go off, show yourself to the priest, and offer what Moses commanded for your cleansing as proof to them." | He says to him, "Look, don't say anything to anyone. Instead, go off, show yourself to the priest, and offer what Moses commanded for your cleansing as proof to them." | He says to him, "Look, don't say anything to anyone. Instead, go off, show yourself to the priest, and offer what Moses commanded for your cleansing as proof to them." |
| 1.45 | However, he went out and began much campaigning and spreading the word so that Jesus couldn't openly go into a city anymore but stayed outside in remote places. They came to him from everywhere. | However, he went out and began much campaigning and spreading the word so that Jesus couldn't openly go into a city anymore but stayed outside in remote places. They came to him from everywhere. | However, he went out and began much campaigning and spreading the word so that Jesus couldn't openly go into a city anymore but stayed outside in remote places. They came to him from everywhere. | However, he went out and began much campaigning and spreading the word so that Jesus couldn't openly go into a city anymore but stayed outside in remote places. They came to him from everywhere. |
Notes
My translation attempts to produce contemporary English while retaining the atmosphere of the Greek. I've used "change your attitude" instead of the somewhat archaic "repent," and "campaign" instead of the rarely used "proclaim" or less vivid "preach." The simple present is used to translate Mark's "historic present." (E.g. "He says to them...")
Sometimes the most frequently supported readings of the four varieties are all the same, as in Mark 1.6 where two witnesses from cluster D have leather instead of hair.
A variation unit may affect more than one verse, as at Mark 1.7-8.
Based on comparison of results presented here, these analysis techniques seem to be robust against loss of information. For example, comparing UBS and INTF results for a data set shows that Greek MSS tend to occupy the same groups when versional and patristic information is omitted. Even so, it is prudent to include as much information as practicable to reduce the risk of missing important relationships.
Some groups are coherent (e.g. Byzantine text, Family 13) while others (e.g. Alexandrian text, Western text, Streeter's “Eastern type”) are diffuse. Coherent groups tend to remain intact when a data set is split into many parts while diffuse groups tend to evaporate. A possible cause of coherence is lack of interference.
Early versions such as the Syriac, Latin, and Coptic are associated with textual varieties such as Streeter's “Eastern type,” the Western text, and the Alexandrian text, respectively. It may be that these versions interfered with the Greek text through the mechanism of back-translation from vernacular to Greek.
...
...
Finally, a plea. Please share information in a format that is useful to others. Given the volume of data and human cost of manual transcription, sharing data as electronic files is a Good Thing. (CSV is a good choice; so is XML.) Please present data sets as data matrices or something like the following XML that can be processed to produce a data matrix using a language such as XQuery:
<apparatus>
<site id="Mk.1.1.1">
<reading code="1">
<text>Χριστου υιου θεου</text>
<attestation>UBS Aleph-1 B D L W 2427</attestation>
</reading>
<reading code="2">
<text>Χριστου υιου του θεου</text>
<attestation>A Delta f-1 f-13 33 180 205 565 579 597 700 892 1006 1010 1071 1243 1292 1342 1424 1505 Byz E F G-supp H Sigma Lect eth geo-2 slav</attestation>
</reading>
<reading code="3">
<text>Χριστου υιου του κυριου</text>
<attestation>1241</attestation>
</reading>
<reading code="4">
<text>Χριστου</text>
<attestation>Aleph Theta 28-c syr-pal arm geo-1 Origen Asterius Serapion Cyril-Jerusalem Severian Hesychius Victorinus-Pettau</attestation>
</reading>
<reading code="5">
<text>omit</text>
<attestation>28 Epiphanius</attestation>
</reading>
<reading code="NA">
<text>undefined</text>
<attestation>it-a it-aur it-b it-c it-d it-f it-ff-2 it-l it-q it-r-1 vg syr-p syr-h cop-sa cop-bo Irenaeus Ambrose Chromatius Jerome Augustine Faustus-Milevis</attestation>
</reading>
</site>
<site id="Mk.1.2.1">...</site>
...
<site id="Mk.16.20.1">...</site>
</apparatus>
Having information that can be electronically processed to produce data matrices allows a broad range of analysis techniques to be applied. If unable to release data matrices then distance matrices are useful, though the range of applicable analysis techniques is narrower. (Tables of percentage agreement or proportional agreement are readily converted to distance matrices.) An important adjunct to distance matrices (or tables of agreements) is a table of counts saying how many data points were used to calculate each distance. Not supplying this information leaves others in the dark concerning the statistical significance of the distances.
Another important aspect is to present apparatus data in a manner that allows presence or absence of all witnesses chosen for citation to be readily established. (See, for instance, the category with text "undefined" in the above XML example.) The UBS Greek New Testament apparatus is most useful in this respect: one knows that if a sometimes cited witness does not appear in an apparatus entry then its reading cannot be established at that place. The Nestle-Aland Novum Testamentum Graece apparatus is less easy to use for constructing data matrices because there are a number of reasons why a witness might not be cited at a variation site:[29]
it is subsumed under the majority text (𝔐)
it does not support the noted reading of a negative apparatus entry
its text is not legible.
In the absence of an algorithm to establish why a witness is not cited at a variation site, this kind of apparatus is not amenable to producing data matrices.
Richard Mallett deserves special thanks for encoding data matrices and transcribing tables of percentage agreement from numerous sources. Compiling the basic data from which analysis proceeds is an arduous and painstaking task, and he has done great service in this respect. Mark Spitsbergen also deserves thanks for helping to encode UBS4 apparatus data for the first fourteen chapters of Matthew.
Maurice A. Robinson kindly provided tables of percentage agreement for the Gospels and Acts. These are derived from the apparatus of the second edition of the United Bible Societies' Greek New Testament. The exacting task of transforming the data into electronic format was performed by Claire Hilliard and Kay Smith.
A number of the results are produced from comprehensive data generously provided by the Institut für neutestamentliche Textforschung in Münster, Germany. Researchers at the INTF have spent many years on the gargantuan task of compiling this data. Holger Strutwolf, Klaus Wachtel, and Volker Krüger were instrumental in providing access to the data.
Thanks go to Gerald Donker for suggesting that the RGL plotting library be used to produce three-dimensional CMDS maps. He also encouraged me to take a less procrustean approach to missing data. As a consequence, the analysis results presented here include many more witnesses than they otherwise would.
The analysis would scarcely have been possible without the marvellous R Language and Environment for Statistical Computing.
Isaac Newton said, “If I have seen further it is only by standing on the shoulders of giants.” This sentiment truly applies to the results presented here. Our field owes a great debt to those who have compiled the information, both printed and electronic, upon which the data and distance matrices are based.
A. Supplementary Information
This appendix provides supplementary information related to analysis results for the data sets:
what proportion of variance is explained by the corresponding three-dimensional CMDS result
the MSW plot obtained by PAM analysis which indicates preferable numbers of groups.
Table A.1. Supplementary information
| Section | Source | Proportion (CMDS) | MSW plot (PAM) |
|---|---|---|---|
| Matthew | Brooks | 0.54 | → |
| CB | 0.73 | → | |
| Cosaert | 0.60 | → | |
| Ehrman | 0.63 | → | |
| INTF-Parallel | 0.28 | → | |
| Racine | 0.69 | → | |
| UBS2 | 0.35 | → | |
| UBS2 (A) | 0.32 | → | |
| UBS4 | 0.53 | → | |
| Wasserman | 0.51 | → | |
| Mark | CB | 0.76 | → |
| Cosaert | 0.63 | → | |
| Hurtado (Mk 1) | 0.76 | → | |
| Hurtado (Mk 2) | 0.82 | → | |
| Hurtado (Mk 3) | 0.76 | → | |
| Hurtado (Mk 4) | 0.82 | → | |
| Hurtado (Mk 5) | 0.76 | → | |
| Hurtado (Mk 6) | 0.81 | → | |
| Hurtado (Mk 7) | 0.85 | → | |
| Hurtado (Mk 8) | 0.83 | → | |
| Hurtado (Mk 9) | 0.79 | → | |
| Hurtado (Mk 10) | 0.82 | → | |
| Hurtado (Mk 11) | 0.77 | → | |
| Hurtado (Mk 12) | 0.81 | → | |
| Hurtado (Mk 13) | 0.82 | → | |
| Hurtado (Mk 14) | 0.83 | → | |
| Hurtado (Mk 15+) | 0.86 | → | |
| Hurtado (P45) | 0.84 | → | |
| Mullen | 0.62 | → | |
| Mullen (P45) | 0.76 | → | |
| INTF-Parallel | 0.33 | → | |
| UBS2 (C) | 0.40 | → | |
| UBS4 | 0.51 | → | |
| UBS4 (control) | 0.16 | → | |
| UBS4 (it-e) | 0.54 | → | |
| UBS4 (it-k) | 0.51 | → | |
| UBS4 (Jerome) | 0.55 | → | |
| UBS4 (non-B) | 0.45 | → | |
| UBS4 (non-Byz) | 0.54 | → | |
| UBS4 (non-f-1) | 0.47 | → | |
| UBS4 (non-it-ff-2) | 0.46 | → | |
| UBS4 (non-vg) | 0.51 | → | |
| UBS4 (Origen) | 0.54 | → | |
| UBS4 (P45) | 0.57 | → | |
| Wasserman | 0.59 | → | |
| Luke | Brooks | 0.45 | → |
| CB | 0.75 | → | |
| Cosaert | 0.57 | → | |
| Fee (Lk 10) | 0.67 | → | |
| INTF-Parallel | 0.27 | → | |
| UBS2 | 0.38 | → | |
| Wasserman | 0.61 | → | |
| John | Brooks (C) | 0.50 | → |
| Brooks (it-j) | 0.47 | → | |
| CB | 0.72 | → | |
| Cosaert | 0.45 | → | |
| Cunningham | 0.54 | → | |
| EFH | 0.61 | → | |
| Fee (Jn 1-8) | 0.80 | → | |
| Fee (Jn 1-8, corr.) | 0.77 | → | |
| Fee (Jn 4) | 0.83 | → | |
| Fee (Jn 4, corr.) | 0.83 | → | |
| Fee (Jn 4, pat.) | 0.60 | → | |
| Fee (Jn 4, pat., corr.) | 0.60 | → | |
| Fee (Jn 9) | 0.89 | → | |
| Fee (Jn 9, corr.) | 0.87 | → | |
| INTF-Parallel | 0.34 | → | |
| UBS2 (Aleph) | 0.33 | → | |
| Wasserman | 0.57 | → | |
| PA | Wasserman | 0.66 | → |
| Acts | Donker | 0.64 | → |
| Donker (Acts 1-12) | 0.66 | → | |
| Donker (Acts 13-28) | 0.67 | → | |
| Osburn | 0.76 | → | |
| UBS2 (Aleph) | 0.40 | → | |
| UBS2 (P45) | 0.36 | → | |
| General Letters | Donker | 0.83 | → |
| James | INTF-General | 0.35 | → |
| 1 Peter | INTF-General | 0.35 | → |
| UBS4 | 0.45 | → | |
| 2 Peter | INTF-General | 0.36 | → |
| 1 John | INTF-General | 0.33 | → |
| Richards | 0.50 | → | |
| UBS4 | 0.40 | → | |
| 2 John | INTF-General | 0.32 | → |
| 3 John | INTF-General | 0.35 | → |
| Jude | INTF-General | 0.32 | → |
| Paul's Letters | Brooks | 0.72 | → |
| Cunningham | 0.70 | → | |
| Donker | 0.70 | → | |
| Osburn | 0.78 | → | |
| Romans | Donker | 0.71 | → |
| 1 Corinthians | Donker | 0.68 | → |
| 2 Corinthians | UBS4 | 0.44 | → |
| 2 Cor. - Titus | Donker | 0.66 | → |
| Hebrews | Donker | 0.72 | → |
| UBS4 | 0.39 | → | |
| UBS4 (B) | 0.41 | → | |
| Revelation | UBS4 | 0.41 | → |
Aland, Kurt, Matthew Black, Bruce Metzger, Allen Wikgren, and Carlo Martini, eds. The Greek New Testament. 2nd ed. Stuttgart: United Bible Societies, 1968.
Aland, Barbara, Kurt Aland, Johannes Karavidopoulos, Carlo M. Martini, and Bruce M. Metzger, eds. The Greek New Testament. 4th rev. ed. Stuttgart: United Bible Societies, 1983.
Aland, Barbara, Kurt Aland, Johannes Karavidopoulos, Carlo M. Martini, and Bruce M. Metzger, eds. Novum Testamentum Graece. Stuttgart: German Bible Society, 1993.
Aland, Barbara, Kurt Aland, Gerd Mink, Holger Strutwolf, and Klaus Wachtel, eds. Novum Testamentum Graecum: Editio Critica Maior. Stuttgart: German Bible Society, 1997-.
Aland, Barbara and Andreas Juckel. Das Neue Testament in syrischer Überlieferung. Vol. 1. Die grossen katholischen Briefe. ANTF 7. Berlin: de Gruyter, 1986.
Anderson, Jared W. “An Analysis of the Fourth Gospel in the Writings of Origen.” ThM thesis, University of North Carolina, 2008.
Brooks, James A. The New Testament Text of Gregory of Nyssa. New Testament in the Greek Fathers 2. Atlanta: Society of Biblical Literature, 1991.
Comfort, Philip W. New Testament Text and Translation Commentary. Carol Stream: Tyndale House, 2008.
Comfort, Philip W. and David P. Barrett, eds. The Text of the Earliest New Testament Greek Manuscripts. Wheaton: Tyndale House, 2001.
Cosaert, Carl P. The Text of the Gospels in Clement of Alexandria. New Testament in the Greek Fathers 9. Atlanta: Society of Biblical Literature, 2008.
Cunningham, Arthur. “The New Testament Text of St. Cyril of Alexandria.” PhD dissertation, University of Manchester, 1995.
Donker, Gerald J. The Text of the Apostolos in Athanasius of Alexandria. New Testament in the Greek Fathers 8. Atlanta: Society of Biblical Literature, 2011.
Ehrman, Bart D. Didymus the Blind and the Text of the Gospels. New Testament in the Greek Fathers 1. Atlanta: Society of Biblical Literature, 1986.
Ehrman, Bart D., Gordon D. Fee, and Michael W. Holmes. The Text of the Fourth Gospel in the Writings of Origen. New Testament in the Greek Fathers 3. Atlanta: Society of Biblical Literature, 1992.
Ehrman, Bart D. and Michael W. Holmes. The Text of the New Testament in Contemporary Research: Essays on the Status Quaestionis. Studies and Documents 46. Grand Rapids: Eerdmans, 1995.
Epp, Eldon J. “The Significance of the Papyri for Determining the Nature of the New Testament Text in the Second Century: A Dynamic View of Textual Transmission.” In Epp and Fee, Studies in Theory and Method, 274-97.
———. “The Twentieth-Century Interlude in New Testament Textual Criticism.” In Epp and Fee, Studies in Theory and Method, 83-108.
———. “The Multivalence of the Term 'Original Text' in New Testament Textual Criticism.” Harvard Theological Review 92, no. 3 (1999): 245-81.
Epp, Eldon J. and Gordon D. Fee. Studies in the Theory and Method of New Testament Textual Criticism. Studies and Documents 45. Grand Rapids: Eerdmans, 1993.
Fee, Gordon D. “Codex Sinaiticus in the Gospel of John: A Contribution to Methodology in Establishing Textual Relationships.” In Epp and Fee, Studies in Theory and Method, 221-43.
———. “P75, P66, and Origen: The Myth of Early Textual Recension in Alexandria.” In Epp and Fee, Studies in Theory and Method, 247-73.
———. “The Text of John in Origen and Cyril of Alexandria: A Contribution to Methodology in the Recovery and Analysis of Patristic Citations.” In Epp and Fee, Studies in Theory and Method, 301-34.
———. “The Use of Greek Patristic Citations in New Testament Textual Criticism: The State of the Question.” In Epp and Fee, Studies in Theory and Method, 344-59.
Finney, Timothy J. “The Ancient Witnesses of the Epistle to the Hebrews.” PhD diss., Murdoch University, 1999. http://purl.org/tfinney/PhD/
———. “Mapping Textual Space.” TC: A Journal of Textual Criticism 15 (2010). http://purl.org/TC/v15/Mapping/
———. “Potential Computer Applications in New Testament Textual Research.” Informal publication, 2011. http://purl.org/tfinney/Potential/
———. “Analysis of Textual Variation.” Informal publication, 2011. http://purl.org/tfinney/ATV/
———. “How To Discover Textual Groups.” Informal publication, 2012. http://purl.org/tfinney/Groups/index.xhtml
Hurtado, Larry W. Text-Critical Methodology and the Pre-Caesarean Text: Codex W in the Gospel of Mark. Studies and Documents 43. Grand Rapids: Eerdmans, 1981.
Lake, Silva. Family Π and the Codex Alexandrinus: The Text according to Mark. Studies and Documents 5. London: Christophers, 1936.
Maechler, M., P. Rousseeuw, A. Struyf, and M. Hubert. “Cluster Analysis Basics and Extensions.” Program documentation for the “cluster” package of R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, 2005.
Mink, Gerd. “Problems of a Highly Contaminated Tradition: The New Testament.” In Studies in Stemmatology II, edited by P. van Reenen, A. den Hollander, and M. van Mulken. Amsterdam: John Benjamins, 2004, 13-85.
———. “The Coherence-Based Genealogical Method: Introductory Presentation.” Münster: Institut für neutestamentliche Textforschung, 2009. http://www.uni-muenster.de/NTTextforschung/cbgm_presentation/
Mullen, Roderic L. The New Testament Text of Cyril of Jerusalem. New Testament in the Greek Fathers 7. Atlanta: Society of Biblical Literature, 1997.
Osburn, Carroll D. The Text of the Apostolos in Epiphanius of Salamis. New Testament in the Greek Fathers 6. Atlanta: Society of Biblical Literature, 2004.
Petzer, Jacobus H. “The Latin Version of the New Testament.” In Ehrman and Holmes, Text of the New Testament in Contemporary Research, 113-30.
R Core Team. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, 2013. http://www.R-project.org/
Racine, Jean-François. The Text of Matthew in the Writings of Basil of Caesarea. New Testament in the Greek Fathers 5. Atlanta: Society of Biblical Literature, 2004.
Richards, W. L. The Classification of the Greek Manuscripts of the Johannine Epistles. SBL Dissertation Series 35. Missoula: Society of Biblical Literature, 1977.
Robinson, Maurice A. “The Determination of Textual Relationships among Selected Manuscripts of the New Testament through the use of Data-Processing Methods.” Unpublished paper in three parts, Southeastern Baptist Theological Seminary, 1972-3.
———. “Textual Interrelationships among Selected Ancient Witnesses to the Book of Acts.” ThM thesis, Southeastern Baptist Theological Seminary, 1975.
Spencer, Matthew, Klaus Wachtel, and Christopher J. Howe, “The Greek Vorlage of the Syra Harclensis: A Comparative Study on Method in Exploring Textual Genealogy.” TC: A Journal of Textual Criticism 7 (2002). http://purl.org/TC/v07/SWH2002/
Saitou, Naruya and Masatoshi Nei. “The Neighbor-Joining Method: A New Method for Reconstructing Phylogenetic Trees.” Molecular Biology and Evolution 4, no. 4 (1987): 406-425.
Sanders, Henry A. The New Testament Manuscripts in the Freer Collection. Part 1, The Washington Manuscript of the Four Gospels. New York: Macmillan, 1912.
Streeter, Burnett Hillman. The Four Gospels: A Study of Origins Treating of the Manuscript Tradition, Sources, Authorship, & Dates. (Eighth impression, 1953. Prefaces to post-1924 impressions incorporate interesting material.) London: Macmillan, 1924.
Strutwolf, Holger and Klaus Wachtel, eds. Novum Testamentum Graecum: Editio Critica Maior: Parallel Pericopes: Special Volume Regarding the Synoptic Gospels. Stuttgart: Deutsche Bibelgesellschaft, 2011.
Wachtel, Klaus. Der Byzantinische Text der Katholischen Briefe: Eine Untersuchung zur Entstehung der Koine des Neuen Testaments. Berlin: de Gruyter, 1995.
———. “Colwell Revisited: Grouping New Testament Manuscripts.” In The New Testament Text in Early Christianity: Proceedings of the Lille Colloquium, July 2000, Histoire du texte biblique 6. Lausanne: Editions du Zèbre, 2003, 31-43.
———. “Conclusions.” In The Textual History of the Greek New Testament: Changing Views in Contemporary Research, edited by Klaus Wachtel and Michael W. Holmes. Text-Critical Studies 8. Atlanta: Society of Biblical Literature, 2011, 217-26.
Wasserman, Tommy. “The Patmos Family of New Testament MSS and Its Allies in the Pericope of the Adulteress and Beyond.” TC: A Journal of Textual Criticism 15 (2010). http://purl.org/TC/v07/Wasserman2002/Wasserman2002.html
[1] Defining the limits of a variation site is a matter of editorial discretion. See “Potential Computer Applications” for a discussion of some approaches.
[2] Gerd Mink provides a definition of the term initial text in “Problems of a Highly Contaminated Tradition,” 25-26. Eldon J. Epp finds the term original text problematic, as discussed in his “Multivalence of the Term 'Original Text.'”
[3] My impression is that the original text's readings are likely to survive among those we know, and that applying the full range of tools now available (including conventional criteria for choosing the best readings) allows us to produce a good approximation to the original text at the level of individual words (though not their spelling). At the semantic level (which is what matters), comparing the archetypal texts (i.e. group representatives) shows that the New Testament is well established, with only a few places where there is a real question about the meaning of the text as handed down from the apostolic generation.
[4] See “Analysis of Textual Variation” for more details of the encoding conventions employed here.
[5] A distance matrix can be obtained from a table of percentage agreement by dividing each percentage by one hundred then subtracting the result from one. For example, a percentage agreement of 85% corresponds to a distance of 0.15.
[6] The vetting algorithm can be forced to retain a particular witness provided it has more than the minimum acceptable number of defined variation sites. The number fifteen is chosen because with this many variation sites a distance estimate of 0.5 has a sampling error of plus or minus 0.233. (In statistical terminology, the critical limits of the 95% confidence interval are 0.267 and 0.733.) That is, when using only fifteen variation sites, the sampling error associated with the distance estimate covers about one half of the entire range of possible distances. The relative size of the sampling error decreases as the number of sites from which the distance is calculated increases. A number less than fifteen may be used so that a particularly important fragmentary witness can be included in a distance matrix.
[7] The R script named control.r produces the control data matrix then dist.r is used to produce the
corresponding distance matrix. Each variable in the control data matrix has only two
possible states whereas more than two can occur in variables (i.e. variation sites) of the
model data matrix. This is not a bad approximation as variables of the model data matrix
often have only two states. The main aim, which is hardly affected by the number of
states, is to produce a control with approximately the same mean distance between objects
as the model. This is achieved using the R expression p = (1
+ (1 - 2*d)^0.5)/2 to calculate the probability p of choosing the
first state (i.e. 1) based on the desired mean distance d. This
p is then used to set the chance of generating a 1 when
c
1s and 2s are generated to form an object. Due to its stochastic
nature, the procedure is unlikely to produce a control with exactly the same mean distance
between objects as the model. However, if many controls were produced and their mean
distances between objects were averaged then the result would tend towards
d.
[8] The limits of the 95% confidence interval for the distance between two randomly
generated objects can be obtained with the R expression
qbinom(c(0.025, 0.975), c, d)/c where c is the number of
variables and d is the mean distance.
[9] See Gerd Mink's “Problems of a Highly Contaminated Tradition” and Introductory Presentation for an explanation of the CBGM.
[11] The bounds were calculated using the R expression
qbinom(c(0.025, 0.975), 123, 0.464)/123. The mean distance between
objects in the model distance matrix is 0.464 and the rounded mean number of variables
in the objects from which that distance matrix was calculated is 123.
[12] CMDS analysis is performed by MVA-CMDS.r. The proportion of variance figure for each CMDS plot is provided in the "Supplementary Information" appendix.
[13] Eldon J. Epp, “Significance of the Papyri,” 291.
[14] In this article, a trajectory refers to a line joining two endpoints in textual space. By contrast, Epp uses the term to describe a time sequence of witnesses with the same kind of text; see e.g. his “Twentieth-Century Interlude,” 93.
[15] Maechler and others, “Cluster Analysis Basics and Extensions”; diana method of the cluster package.
[16] DC analysis is performed by MVA-DC.r using the distance matrix and a table of counts which gives the number of variation sites covered by each witness.
[17] Branching heights correspond to distances between the clusters constituted by the branches. The upper critical limit calculation and partitioning are performed by MVA-DC.r. The order of groups is determined by the program and is not significant.
[18] Naruya Saitou and Masatoshi Nei, “The Neighbor-Joining Method,” 406-7.
[19] NJ analysis is performed by pheno-NJ.r.
[20] See documentation relating to the pam method of the cluster package by Maechler and others, “Cluster Analysis Basics and Extensions.”
[21] PAM analysis is performed by MVA-PAM.r. There is no particular reason for making the largest number of groups twelve. Smaller numbers of groups tend to retain peripheral members while larger numbers tend to produce unwieldy tables of results.
[22] The MSW plot is produced by MVA-PAM-MSW.r. This script also identifies numbers of groups corresponding to peaks with above-average MSW values. An MSW plot for each data set is provided in the "Supplementary Information" appendix.
[23] Systematic bias can be introduced by editorial practices that treat one group differently to another.
[24] The script rank.r allows ranked distance results to be obtained for any witness included in a distance matrix. This script requires a distance matrix and list of counts of readings per witness in the distance matrix, which are found in the dist directory of this web site.
[25] Streeter (1924), 64.
[26] Frederik Wisse, Profile Method, 52-90.
[27] Aland and others, Greek New Testament (4th ed.), 2*.
[28] Minuscule 2427, which is now considered to be spurious, has been dropped from the B cluster so that it does not affect decisions on cluster membership.
[29] Aland and others, Novum Testamentum Graece (27th ed.), 51*.