Table of Contents
This article suggests ways that certain computer technologies can be applied in the field of New Testament textual research. Emphasis is placed on the following areas:
XML and related technologies
analysis using the R Language and Environment for Statistical Computing.
Applications will be covered under the headings of data storage, collation, and analysis. In addition, a section will be devoted to a possible implementation of the Coherence-Based Genealogical Method (CBGM) developed at the Institut für neutestamentliche Textforschung (INTF).[1] This implementation would allow individual users to customize the set of stemmata used to determine witness priorities. A short description of XML and related technologies will precede discussion of potential applications.
![[Note]](file:/opt/Oxygen%20XML%20Editor%2011/frameworks/docbook/xsl/images/note.png) | Note |
|---|---|
I would like to acknowledge the help of Klaus Wachtel of the INTF who suggested a number of improvements to this article, particularly in the section on the Coherence-Based Genealogical Method. |
According to the World Wide Web Consortium (W3C),
Extensible Markup Language (XML) is a simple, very flexible text format derived from SGML (ISO 8879). Originally designed to meet the challenges of large-scale electronic publishing, XML is also playing an increasingly important role in the exchange of a wide variety of data on the Web and elsewhere.[2]
The dual strengths of XML as an aid to electronic publication and as a data storage and exchange format can be usefully applied to certain tasks in New Testament textual research.
In terms of data structure, every XML document is a “tree.” That is, it consists of a hierarchy of nested elements called “nodes” or branching points. For this reason, XML is a natural language for describing stemmata:
Example 1. XML Representation of a Stemma
The following figure shows a stemma, which is an example of a data structure called a tree:
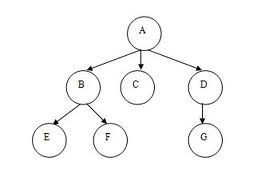
This stemma can be represented using XML:
<stemma>
<node>A
<node>B
<node>E</node>
<node>F</node>
</node>
<node>C</node>
<node>D
<node>G</node>
</node>
</node>
</stemma>
This uses “stemma” and “node” elements to represent the
stemma. Each element has an opening (e.g. <stemma>) and closing
(e.g. </stemma>) tag.
The nodes in the example above have mixed content, meaning that text and elements are interspersed. The same stemma can be represented another way to avoid mixed content:
<stemma>
<node n="A">
<node n="B">
<node n="E"/>
<node n="F"/>
</node>
<node n="C"/>
<node n="D">
<node n="G"/>
</node>
</node>
</stemma>
This time, “n” attributes are used to label the nodes of the stemma. A
number of the nodes do not contain other nodes (e.g. E, F, G) and therefore use
“empty element” notation (e.g. <node n="E"/>).
There is no requirement to use this notation so each empty element could employ opening
and closing tags instead (e.g. <node n="E"></node>). There is
always “more than one way to do it” when representing real-world objects with
XML.
There are numerous XML-related technologies. Some of the most important include XSLT, XPath, and XQuery.[3] These allow XML data to be processed in various ways, perhaps transforming XML into HTML or PDF formats for display on the Web, or querying an XML database to compile useful information from a large number of records.
XML is a natural language for describing stemma but can equally be applied to represent something as complex as a transcription of a New Testament manuscript. The Text Encoding Initiative Consortium produces the Guidelines for Electronic Text Encoding and Interchange which is currently at the edition labelled “P5.”[4] The current version of the TEI Guidelines is the product of decades of thought and refinement by humanities scholars who work with electronic texts. Its XML pedigree is second to none, with a former editor of the Guidelines also being an editor of the XML specification itself.[5] Built in a modular structure, certain sections are relevant to storage of information on New Testament manuscripts, namely:
Chapter 10: Manuscript Description
Chapter 11: Representation of Primary Sources
Chapter 12: Critical Apparatus
Chapter 21: Certainty, Precision, and Responsibility.
The chapter titled “Representation of Primary Sources” is particularly relevant to manuscript transcription while the one titled “Certainty, Precision, and Responsibility” describes useful conventions for treating uncertain items such as a phrase labelled “vid.” in the apparatus of a critical edition.
One problem in applying the Guidelines to a given task is the range of encoding methods available, even within a narrow field. (There is always “more than one way to do it.”) For this reason, some “guides to local practice” have been developed to specify markup style for commonly encountered scenarios within a particular context. The following two are representative:
Further discussion concerning the use of TEI XML to transcribe New Testament manuscripts can be found in the “Manuscript Markup” chapter of Larry Hurtado's book on The Freer Biblical Manuscripts.[6]
A particularly important area of New Testament textual research relates to intercomparison of witnesses. Computers have great potential to assist in the exploration of relationships among the numerous textual forms that survive among extant witnesses. However, before the exploration can begin it is necessary to adapt the data so that it is amenable to intercomparison by computer means:
orthographic variation must be levelled through a process called normalization or regularization
milestones must be inserted to help a computer identify parallel passages across witnesses
uncertain words and phrases must be presented in a form that does not hinder intercomparison.
Normalization can be an enormous task. There is a vast spectrum of orthographic variation, every aspect of which must be identified and properly levelled. At the same time, the orthographic complexion of a witness is an important consideration when it comes to identifying relationships among witnesses.[7] Consequently, it is desirable to record the orthographic peculiarities of each witness and to have a painless way to level them. Both desiderata can be realised by transcribing a witness with all of its quirks to produce an “orthographic” version then running this through a program that identifies and substitutes standard orthography to produce a “substantive” version.[8] Given a number of existing substantive versions of the text, it would be relatively straightforward to write a program that compared a particular orthographic version on a verse by verse basis to make a one-to-one mapping from each word in the orthographic version to a single word found in the same verse of the substantive versions. In order to do this, the notional distance could be calculated between a word in the orthographic version and every word in the same verse for all of the substantive versions.[9] The word in the same verse of the substantive versions with the smallest distance to the word under examination in the orthographic version would then be identified as equivalent. The result would be a substantive version of the orthographic version under examination.
This method is not infallible:
more than one potential equivalent may have the same distance to a word in the orthographic version
the appropriate equivalent may not yet be contained in the same verse of the substantive versions used as a reservoir for potential matches
the appropriate equivalent may be a greater distance from the word in the orthographic version than an inappropriate one.
In the first case, the program could generate a report which flags places where a mind that understands grammar needs to decide which alternative is the appropriate normalized form. Failures of the second kind would be harder to identify. One possibility would be to set an upper threshold for the distance measure and flag places where this threshold was exceeded. Nevertheless, it would remain possible for an incorrect equivalent with a distance below the threshold to be substituted. There would be no simple way to detect errors of the third kind. The only way to correct remaining errors of the second and third kinds would be through proof-reading every substantive version generated by the process. While this may be too much to expect of a small group of individuals, it may be achievable by making the substantive versions available to a large readership through the Internet.
It may not be long before computers and software develop to the point where they begin to interpret texts with the same grammatical acuity as an expert human. However, until this happens it will be necessary to manually insert milestones into transcriptions so that computers can identify parallel locations in a series of texts. The book, chapter, and verse divisions already employed as standard milestones for the biblical text go some way towards this goal. However, something more fine-grained than verse-level division is required to adequately demarcate the “variant passages” or “variation units” that act as lemmas in critical editions.
Identifying the limits of a variant passage is more of an art than a science. Fundamentally, a set of notionally independent places where variations on a theme occur among extant witnesses is identified. As the number of compared witnesses increases, the number of variation units tends to increase and the extent of each one tends to decrease. To take the most comprehensive critical edition of the New Testament as an example, the fascicles of the INTF's Editio Critica Maior (ECM) which cover the General Letters identify 3061 variant passages in 432 verses, a ratio of about seven variant passages per verse.[10]
The large number of variant passages identified in the ECM indicates that, as a general rule and given enough hand-copies of a text, any place where variation can happen does eventually manifest alternative readings.[11] This suggests that one way to divide a text is to identify every grammatical unit which functions as a part of speech. Every such “potential variation unit” is, then, a place where variation might be expected to occur given enough hand-copies.
Example 2. Dividing a text into potential variation units
The following saying, often attributed to Groucho Marx, is subtle enough to test any notion of how a text should be divided into potential variation units: “Time flies like an arrow; fruit flies like a banana.” A number of divisions are possible depending on how one construes the words:
both instances of “flies” are interpreted as verbs:
<phrase>
<pvu>Time</pvu>
<pvu>flies</pvu>
<pvu>like</pvu>
<pvu>an arrow</pvu>
<pvu>;</pvu>
<pvu>fruit</pvu>
<pvu>flies</pvu>
<pvu>like</pvu>
<pvu>a banana</pvu>
<pvu>.</pvu>
</phrase>
“fruit flies” is interpreted as a noun phrase:
<phrase>
<pvu>Time</pvu>
<pvu>flies</pvu>
<pvu>like</pvu>
<pvu>an arrow</pvu>
<pvu>;</pvu>
<pvu>fruit flies</pvu>
<pvu>like</pvu>
<pvu>a banana</pvu>
<pvu>.</pvu>
</phrase>
“time flies” and “fruit flies” are interpreted as noun phrases:
<phrase>
<pvu>Time flies</pvu>
<pvu>like</pvu>
<pvu>an arrow</pvu>
<pvu>;</pvu>
<pvu>fruit flies</pvu>
<pvu>like</pvu>
<pvu>a banana</pvu>
<pvu>.</pvu>
</phrase>
In this example, places where punctuation occur are treated in the same way as potential variation units which relate to words. Also, while the third interpretation is unlikely because there is no such thing as an insect called a “time fly,” it is still a plausible grammatical construction. In addition, this example shows that the function performed by one unit can be affected by the interpretation placed on another. To illustrate, the word “like” functions in different ways depending on whether “flies” is construed as a verb or part of a noun phrase.
Another way to demarcate variation units is by determining where there is no variation among witnesses. This method becomes less useful as more witnesses are collated because the likelihood of variation occurring anywhere it can conceivably happen increases with the number of witnesses. The number of places where the text is static (i.e. unvarying) therefore decreases as more witnesses are considered. This presents a problem when it comes to intercomparison because every witness tends to become more singular in its readings as adjacent variation units are combined. To put it another way, the probability of perfect agreement between any pair of witness decreases rapidly as the extent of a variation unit increases. By contrast, the more granular the division into variation units, the more often community of attestation occurs among witnesses at every variation unit.
Yet another approach to demarcation is the tried and true method of applying human intuition to the problem. This seems to be the way that most editors have identified variation units up until the present time.
Once a canonical sequence of variation units and sections of static text has been determined, it is necessary to insert milestones which demarcate the variation units in every parallel text to be compared. This is a potentially enormous task because the milestones need to be inserted at the appropriate places in every parallel text before a computer with no grammatical awareness can be used for intercomparison. A similar strategy to the one suggested above for normalization could be applied to this task as well. This time, the procedure would use a reservoir of substantive versions of the parallel texts which are already equipped with a full complement of variation unit milestones to identify places where corresponding milestones must be inserted into a text which does not yet have them.[12]
Various challenges would face anyone seeking to write a program that inserts variation unit milestones. For one thing, the presence of existing XML markup could frustrate the process due to the potential for producing invalid XML if a variation unit boundary occurred within an existing XML element. (E.g. a boundary may occur within a span of text marked as uncertain.) A simple way to avoid this problem would be to use pairs of empty elements to mark the beginning and end of every variation unit. However, this would add a layer of programming complexity when it came to extracting corresponding variation units from a collection of parallel texts which were being compared. Nevertheless, it could be done.
For another thing, it would be necessary to handle situations where the substantive version being processed had a reading which was not found among the reservoir of substantive versions. This could be handled by flagging such occurrences for later manual intervention by a human. No doubt there would be other challenges that would only become apparent when someone tried to write a program to do this job.
A number of kinds of uncertainty exist in relation to the texts of New Testament witnesses. Sometimes writing is hard or impossible to read. Also, a number of scribes and correctors may have been at work, making it difficult to discern who is responsible for what. Another class of uncertainty relates to translation from a version back to Greek so that all witnesses can be compared on the same footing; sometimes it is hard to tell which Greek text stands behind a translation of the same passage.
While the TEI Guidelines specify a number of ways to mark up instances of uncertainty, some are less useful than others when the resulting transcription will form part of a collection of parallel texts to be compared. In this case, it is better to express uncertain text in a way that takes account of known parallels. It is reasonable to let known parallels narrow the range of alternatives that conform to what can be discerned of an uncertain text. Even though many potential readings might be imagined where a text is uncertain, not all are probable. An overarching tendency among New Testament manuscripts is for the range of readings in a variation unit to be restricted to a small number of alternatives. In view of this, it makes sense to choose as the most likely possible readings of an uncertain section of text those which are consistent with readings found among parallel texts at the same location.
The choice of the most probable reading of an uncertain section of text could be made part of the normalization process which converts an orthographic version of a transcription to a substantive one. In order to do this, a distance could be calculated between what is discernible of an uncertain text and potential parallels found among a reservoir of existing substantive versions over the same stretch of text.
Example 3. Choosing the most probable reading of an uncertain text
Say that three versions of a text exist:
one substantive version with variation unit milestones already inserted:
<verse>Time flies like an arrow; fruit flies <vu>like</vu> <vu>a banana</vu>.</verse>
another substantive version with variation unit milestones:
<verse>Time flies like an arrow; fruit flies <vu>enjoy</vu> <vu>an apple</vu>.</verse>
an orthographic version which has not yet been converted to a substantive one:
<verse>Tyme flys lyke an arrow; froot flys en<uc>??????</uc>nan<uc>?</uc>.</verse>
Here, <uc>...</uc> indicates uncertain text and
<vu>...</vu> a variation unit. During the normalization
process, orthographic variations would be levelled and all possible combinations of known
readings compared with uncertain text in the affected section. The closest readings at
every relevant variation unit would then be used as suggested readings:
<verse>Time flies like an arrow; fruit flies <vu><uc>enjoy</uc></vu> <vu><uc>a banana</uc></vu>.</verse>
This example is for illustrative purposes only. In reality, one of the appropriate TEI tags would be used for the uncertain text, which would have a number of levels of uncertainty corresponding to those used when transcribing text according to the Leiden conventions. (That is, dotted text for doubtfully read, bare dots for illegible, and braces for lacunae.)
Potential traps would need to be detected and flagged if possible. For example, the uncertain text may preserve a singular reading or the remnant may be equally consistent with more than one possible combination of known readings.
Before concluding this section, it is worth noting that numerous computer-assisted collation tools have been written using a range of collation methods.[13]
Given a collection of parallel texts which have been normalized to deal with orthographic
variation and uncertain text, it is possible to produce from them a “data matrix”
which uses symbols to represent the reading of each witness at every variation unit. The
symbols may be numerals or letters. If letters are used and there is more than 26 readings
then more than one letter can be used to represent the state of a text at a variation unit
(e.g. “ac”). If the reading of a witness at a particular variation unit cannot be
determined with confidence then the code NA can be employed to indicate that it
is not available.
Example 4. Part of a data matrix
Part of a data matrix derived from the apparatus of the Epistle to the Hebrews in the UBS Greek New Testament (UBSGNT) is presented here:[14]
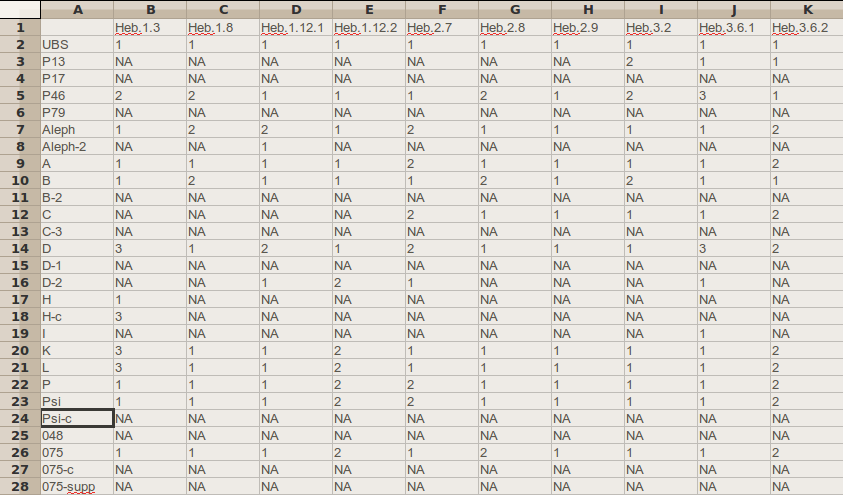
By counting the number of agreements between a pair of witnesses across a number of mutually-defined variation units (i.e. variation units where the readings of both witnesses can be read with an acceptable degree of confidence), it is possible to calculate a distance between each pair. One suitable way to calculate the distance is called the “simple matching measure.” This takes the ratio of agreements to mutually defined variation units and subtracts it from one to obtain a distance that ranges from zero for complete agreement to one for complete disagreement. In the interests of avoiding too large a sampling error, it is best to only calculate the distance for every pair of witnesses which shares more than a tolerable minimum number of mutually defined variation units.
Example 5. Part of a distance matrix
Part of a distance matrix derived from a database that belongs to the INTF is presented below. It relates to the First Letter of Peter:

A number of multivariate analysis techniques can be employed to explore the relationships between witnesses implied by the information in a distance matrix. The following two examples present results obtained by analysing the preceding distance matrix using two techniques called classical multidimensional scaling and divisive clustering:

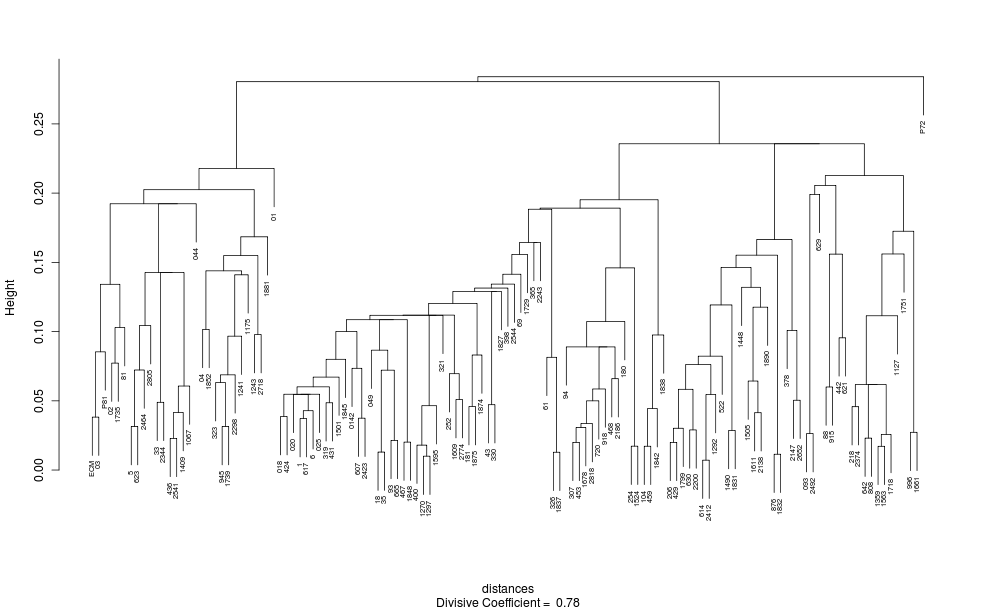
The analysis that produced these results was performed using the R Language and Environment for Statistical Computing. Numerous other multivariate analysis techniques can be applied in the same way, each giving its own perspective on the information contained in the distance matrix.
The INTF's coherence-based genealogical method (CBGM) seeks to determine the relative priorities of the textual states preserved in extant witnesses. Gerd Mink, who invented the CBGM, has written a comprehensive introduction, “The Coherence-Based Genealogical Method: Introductory Presentation.” While developed to seek the initial text of the New Testament, there is no reason why this method could not be fruitfully employed to better understand other textual traditions such as the Hebrew Bible or Homeric writings.
The method begins with a set of stemmata, each showing the supposed ancestry of readings within a variation unit. Every stemma in the set represents an opinion concerning the most probable line of descent from an initial reading to the rest. The stemmata are expressed as simple trees, and the possibility that the same reading may arise at more than one place in a tree is admitted.
All available information can be taken into consideration when the hypothetical stemma of a variation unit is being constructed:
known scribal tendencies
the extent of dissemination of a reading into diverse parts of the tradition
the attestation of each reading in a variation unit.
| Note |
|---|---|
The attestation of a reading (i.e. the list of extant witnesses which support the reading) might include non-Greek versions and patristic citations along with Greek manuscripts. It is often possible to discover relationships between readings by carefully examining levels of agreement (“pre-genealogical coherencies”) between witnesses in the attestation lists. Gerd Mink provides an example of this deductive process at pages 180-92 of his “Introductory Presentation.” |
Once stemmata have been proposed for a number of variation units, the method determines the priority of each witness relative to every other one. This is achieved by counting how often the readings of a first witness seem to be derived from the readings of a second witness compared with how often readings of the second seem to be derived from the first. The counting is based on the relative priorities of the two witnesses in each one of the postulated stemmata, and, in order to do the counting, it is necessary to consider the attestation for each reading.
Example 8. Relative priority of two witnesses
According to stemmata proposed by the INTF for the First Letter of Peter, readings found in minuscule 33 are thought to derive from those found in majuscule 03 in 42 cases. By contrast, readings found in 03 are thought to derive from those found in minuscule 33 in 18 cases.[15] The relative frequency with which readings found in 03 are derived from those in 33 is therefore 18 / (18 + 42) = 0.3. This indicates that the text preserved in majuscule 03 is prior to that preserved in minuscule 33.[16]
As the results obtained by this method depend on the postulated stemmata, it would be useful to have a facility that allowed a number of experts and other interested parties to experiment with the method by suggesting their own sets of stemmata. Such a facility would enable a range of interesting scenarios and theories of the text to be tested. One could test how consistently the text preserved in one witness was determined to be prior to that preserved in another when competing theories about scribal practice were expressed in the stemmata. Also, by prudently selecting variation units, a particular phenomenon such as conflation could be examined to see whether one form of the text (e.g. “Byzantine”) exhibited the phenomenon more frequently than another (e.g. “proto-Alexandrian”).
Implementing such a facility using XML technology would be reasonable straightforward. The first step would be to express every variation unit as a set of readings and to list the attestation of each reading.
Example 9. XML representation of a variation unit and its readings
A variation unit affecting words near the end of 1 Peter 1:1 has 10 readings:
<vu id="1.Peter.1.1.20-26">
<rdg n="a" attestation="P72 P74V 01C2 ... Byz 88C PsOec L:V">καππαδοκιασ ασιασ και βιθυνιασ</rdg>
<rdg n="b" attestation="614 621 1292 ... L596 S:H-ms Sl:ChDMS">καππαδοκιασ και ασιασ και βιθυνιασ</rdg>
<rdg n="c" attestation="307 330 453 ... 2805 2818 A-mss">και καππαδοκιασ ασιασ και βιθυνιασ</rdg>
<rdg n="d" attestation="88*V 1243 2492 L:S S:H-ms A-mss">και καππαδοκιασ και ασιασ και βιθυνιασ</rdg>
<rdg n="e" attestation="876 1409T 1832">καππαδοκιασ ασιασ βιθυνιασ</rdg>
<rdg n="f" attestation="01* 048 1838 G:A1">καππαδοκιασ και βιθυνιασ</rdg>
<rdg n="g" attestation="03">καππαδοκιασ ασιασ</rdg>
<rdg n="h" attestation="1175">και καππαδοκιασ</rdg>
<rdg n="i" attestation="Cyr K:S-ms">ασιασ και βιθυνιασ</rdg>
<rdg n="j" attestation="1241"/>
</vu>
| Note |
|---|---|
This example is extracted from the complete version of the variation unit given in
Aland et al., ECM: Catholic Letters: Text: The Letters of Peter,
104. The example only gives the first and last few entries of the attestation lists for
the first three readings. The identifier ( |
Certain ambiguities would have to be dealt with when recasting variation units as XML. For example, a decision whether to admit an attestation would be required whenever a witness was marked as uncertain (e.g. P74V in reading “a”). Also, a policy would have to be developed concerning how to handle splits within a version (e.g. A-mss vs A-mss in readings “c” and “d”). Instances where the first hand is distinguished from a corrector by means of an asterisk would need to be replaced with the bare siglum (e.g. “01*” would be replaced with “01”).
Once the variation units were encoded as XML, it would be possible for a user of the facility to inspect them and choose a subset that suited her particular research interest. Operating in a “sandbox” area which was reserved for her exclusive use, she would then be able to construct a stemma for each variation unit according to her own understanding of the way that readings evolve. There would be no need to include every reading of a variation unit in any given stemma. Instead, the researcher might choose to include only those readings for which it was possible to make confident assertions concerning priority.
A facility of this kind would be efficient in terms of storage because all that would be necessary to store for each user would be the corresponding set (or sets) of XML representations of customized stemmata — a very small storage footprint.[17]
What would make or break the facility would be ease of use in selecting a set of variation units and specifying a stemma for each one. One can imagine a user going through the following steps in a typical session:
Log in.
Navigate to a place where customized sets of stemmata are created, edited, and, perhaps, deleted.
Open a particular customized set and continue the process of specifying which readings are descended from which.
Log out.
In another session, the user might decide to create a new customized set by choosing suitable variation units from the reservoir maintained by the administrators of the system.
Usability is a crucial consideration. Users would soon grow tired of the facility if it was too hard to customize the stemmata. On the other hand, if there was a well-designed graphical interface that made it easy to enter stemmata then the facility could be expected to attract more and more users.
Once the stemmata were specified for a particular customized set, the researcher could press “Go” and see what eventuated. Behind the scenes, an XQuery script would look at every pair of witnesses contained in the attestations of all of the variation units covered by the customized set, calculating for each pair the relative frequency with which the first member was higher than the second member in the user-specified stemmata. The basic result would be a listing of relative priorities of pairs of witnesses. This listing could then be used to generate further results of the kind presently available through the INTF's “Genealogical Queries” program.
A facility of the kind imagined here would have other uses as well. For example, if the stretches of static text which occur between variation units were included as well then it would be a straightforward exercise to extract the normalized text of any witness contained in the database. There is tremendous potential for such a facility to advance our understanding of the New Testament textual tradition.
Aland, Barbara, Kurt Aland, Johannes Karavidopoulos, Carlo M. Martini, and Bruce M. Metzger, eds. The Greek New Testament. United Bible Societies, 4th rev. ed. Stuttgart: Deutsche Bibelgesellschaft, 1993.
Aland, Barbara, Kurt Aland†, Gerd Mink, Holger Strutwolf, and Klaus Wachtel, eds. Novum Testamentum Graecum: Editio Critica Maior. Stuttgart: Deutsche Bibelgesellschaft, 1997-.
———. Novum Testamentum Graecum: Editio Critica Maior. Volume 4: Catholic Letters. Part 1: Text. Installment 2: The Letters of Peter. Stuttgart: Deutsche Bibelgesellschaft, 2000.
Bray, Tim, Jean Paoli, C. M. Sperberg-McQueen, Eve Maler, François Yergeau. Extensible Markup Language (XML) 1.0. 5th ed. World Wide Web Consortium, 2008. http://www.w3.org/TR/2008/REC-xml-20081126/.
Burnard, Lou and Syd Bauman. P5: Guidelines for Electronic Text Encoding and Interchange. http://www.tei-c.org/release/doc/tei-p5-doc/en/html/.
EpiDoc Contributors. “EpiDoc: Guidelines for Structured Markup of Epigraphic Texts in TEI.” http://www.stoa.org/epidoc/gl/5/.
Finney, Timothy J. “Converting Leiden-style editions to TEI Lite XML.” http://www.tei-c.org/Support/Learn/leiden.html.
———. “Manuscript Markup.” In The Freer Biblical Manuscripts: Fresh Studies of an American Treasure Trove, edited by Larry Hurtado, 263-87. Atlanta: SBL, 2006.
Mink, Gerd. “Problems of a Highly Contaminated Tradition: The New Testament.” In Studies in Stemmatology II, edited by P. van Reenen, A. den Hollander, and M. van Mulken, 13-85. Amsterdam: John Benjamins, 2004.
———. “The Coherence-Based Genealogical Method: Introductory Presentation.” Münster: Institut für neutestamentliche Textforschung, 2009. http://www.uni-muenster.de/NTTextforschung/cbgm_presentation/.
Raabe, Wesley. “Collation in Scholarly Editing: An Introduction.” http://wraabe.wordpress.com/2008/07/26/collation-in-scholarly-editing-an-introduction-draft/.
Schmidt, Desmond. “Merging Multi-Version Texts: A General Solution to the Overlap Problem.” In Proceedings of Balisage: The Markup Conference 2009. Vol. 3. Balisage Series on Markup Technologies. 2009. http://www.balisage.net/Proceedings/vol3/html/Schmidt01/BalisageVol3-Schmidt01.html.
Wachtel, Klaus and Volker Krüger. “Genealogical Queries.” Münster: Institut für neutestamentliche Textforschung, 2008. http://intf.uni-muenster.de/cbgm/en.html.
Wikipedia Contributors. “Damerau–Levenshtein Distance.” Wikipedia, The Free Encyclopedia. http://en.wikipedia.org/wiki/Damerau–Levenshtein_distance.
———. “XML.” Wikipedia, The Free Encyclopedia. http://en.wikipedia.org/wiki/XML.
———. “XPath.” Wikipedia, The Free Encyclopedia. http://en.wikipedia.org/wiki/XPath.
———. “XQuery.” Wikipedia, The Free Encyclopedia. http://en.wikipedia.org/wiki/XQuery.
———. “XSLT.” Wikipedia, The Free Encyclopedia. http://en.wikipedia.org/wiki/XSLT.
World Wide Web Consortium. “Extensible Markup Language (XML).” http://www.w3.org/XML/.
[1] Gerd Mink describes the CBGM in “The Coherence-Based Genealogical Method: Introductory Presentation” and “Problems of a Highly Contaminated Tradition.”
[2] World Wide Web Consortium, “Extensible Markup Language (XML).”
[3] Further details can be found in the Wikipedia entries for XSLT, XPath, and XQuery. Some other XML-related technologies are listed in the Wikipedia article on XML.
[4] Burnard and Bauman, P5: Guidelines for Electronic Text Encoding and Interchange. “P5” stands for “Proposal 5.”
[5] Michael Sperberg-McQueen of the World Wide Web Consortium is one of the original editors of the XML specification. He is also one of the original editors of the TEI Guidelines, along with Lou Burnard of Oxford University Computing Services who still serves in this capacity.
[6] See Finney, “Manuscript Markup.” Associated electronic files which relate to the transcription of part of the Washington Manuscript of Paul are available from the SBL's Additional Material page.
[7] My PhD research suggests that similar results are obtained when comparing witnesses from the dual perspectives of orthographic and substantive variation. (Substantive variation is that which affects the meaning of the text; orthographic variation affects the surface form but not the meaning.) This outcome may be interpreted to mean that the tradition preserves localized texts and spellings.
[8] See the preceding footnote for a definition of orthographic and substantive variation.
[9] There is an algorithm for calculating the distance from one word to another. It counts the number of addition, deletion, substitution, and transposition steps necessary to transform the first word into the second. The algorithm is described in the Wikipedia article on the Damerau–Levenshtein distance.
[10] See Aland et al., Novum Testamentum Graecum: Editio Critica Maior. The number of variant passages was kindly supplied by Klaus Wachtel.
[11] This is not to say that it is impossible to establish a close approximation to the text which stood at the beginning of the surviving manuscript tradition. Most variation units have only a few viable readings and it is often possible to be confident about which reading gave rise to the others within a variation unit.
[12] The method could also be used to place the milestones into the orthographic version of a text by reference to its substantive version and the one-to-one mapping of orthographic to substantive word forms in a verse.
[13] Examples include Collate, Juxta, and nmerge. Desmond Schmidt, the developer of nmerge, surveys collation algorithms in “Merging Multi-Version Texts.” Wesley Raabe lists a number of computer-assisted collation tools in “Collation in Scholarly Editing.”
[14] Aland et al. Greek New Testament.
[15] The total number of specified cases (i.e. 42 + 18 = 60 instances) is less than the number of variation units where readings are recorded for these two witnesses (i.e. 617 instances) because an assessment of priority has not been made for every variation unit.
[16] A relative frequency of derivation which is less than 0.5 indicates that the first witness is prior to the second.
[17] Not that anyone cares about efficient use of storage space any more.